
If you manage multiple accounts through TreasuryDirect.gov to purchase T-bills, T-notes, T-bonds, TIPS, FRNs, or C of I certificates then you know how antiquated and difficult it can be to manage all of your accounts at the United States Treasury. I’ve written a Python program to aggregate all of these accounts into a single summary Excel document. This program can be expanded to buy and sell securities. However, in its published state is simply aggregates all the data and returns it to a CSV file.
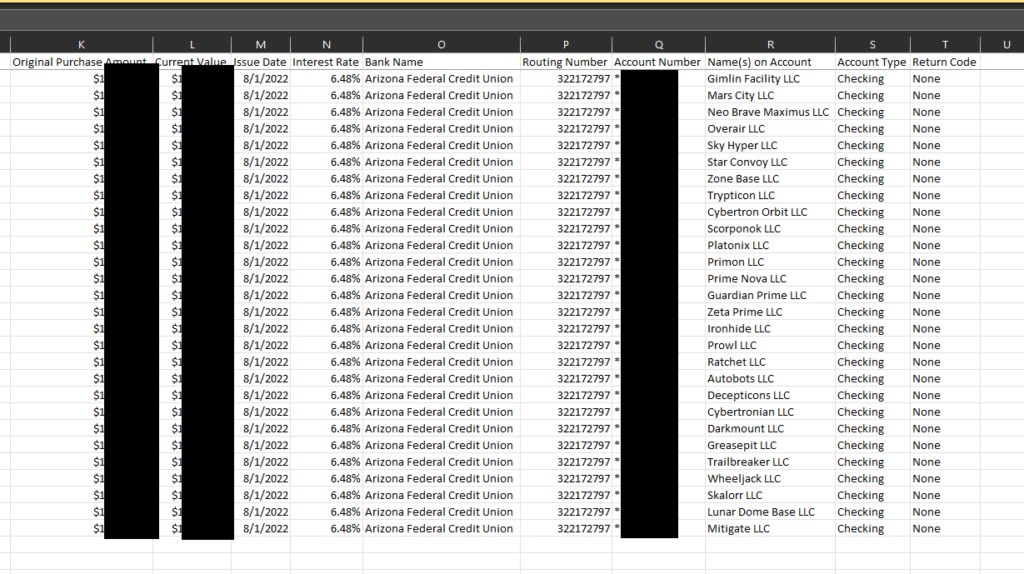
The program is written in Python and uses the Selenium WebDriver to interact with the TreasuryDirect.gov website. The program is designed to work with multiple accounts, and it reads the account information from a CSV file. It also has a feature to bypass the one-time password by logging in to your email and extracting the OTP. The program works by logging in to each account, checking the account details, and updating the account information as needed. It currently returns the following data:
Automating the login to each account
To do this, the program reads a CSV file containing all of your TreasuryDirect.gov account numbers and other relevant information, such as LLC names and purchase amounts. It then loops through each account, retrieves the necessary information from the TreasuryDirect.gov website using Selenium, and saves the data into a new column of the CSV file.
Here’s an example of the code that performs this task:
import pandas as pd
from treasury_direct import process_account
if __name__ == '__main__':
df = pd.read_csv('accounts.csv')
url = "https://www.treasurydirect.gov/RS/UN-Display.do"
for index, row in df.iterrows():
account_number = row['Treasury Direct']
# Check if the row is already complete
if not pd.isna(row['LLC Name']) and not pd.isna(row['Original Purchase Amount']) \
and not pd.isna(row['Current Value']) and not pd.isna(row['Issue Date']) \
and not pd.isna(row['Interest Rate']):
continue
success = process_account(account_number, df, index, url)
if success:
time.sleep(60)
df.to_csv('accounts.csv', index=False)
Automatically retrieving one-time passcodes (OTPs) from emails
To log into each account, the program needs to retrieve OTPs from emails sent by TreasuryDirect.gov. It uses the Gmail API to search for unread emails from TreasuryDirect.gov containing the subject line “One Time Passcode” and retrieves the OTP from the email body. Once it has the OTP, the program enters it into the appropriate field on the TreasuryDirect.gov login page.
Here’s an example of the code that retrieves OTPs:
from gmail import get_otp
# Perform the one-time password process here
# Enter the OTP in the input field
# Continuously try to get OTP from the email until it's received
otp = None
while otp is None:
otp = get_otp()
if otp is None:
# Sleep for 10 seconds before trying again
time.sleep(10)
otp_input = driver.find_element_by_name("otp")
otp_input.send_keys(otp)
Finding the OTP in the email
else:
# Get the first unread email
message = messages[0]
msg = service.users().messages().get(userId='me', id=message['id'], format='full').execute()
msg_str = base64.urlsafe_b64decode(msg['payload']['body']['data']).decode()
otp = msg_str.splitlines()[6].split()[0]
if otp:
one_time_passcode = otp
print(f"{one_time_passcode}")
return one_time_passcode
else:
print("No One Time Passcode found in the email.")
return None
Moving OTP emails to trash
To avoid cluttering your inbox, the program moves OTP emails to the trash folder after retrieving the OTPs. It uses the Gmail API to search for emails from TreasuryDirect.gov containing the subject line “One Time Passcode” and moves them to the trash folder.
Here’s an example of the code that moves OTP emails to trash:
def move_otp_emails_to_trash():
try:
creds = get_credentials()
service = build('gmail', 'v1', credentials=creds)
results = service.users().messages().list(userId='me',
q='from:Treasury.Direct@fiscal.treasury.gov subject:"One Time Passcode"').execute()
messages = results.get('messages', [])
if not messages:
print('No messages found.')
else:
for message in messages:
service.users().messages().trash(userId='me', id=message['id']).execute()
print(f"Moved message with ID {message['id']} to trash.")
except HttpError as error:
print(f'An error occurred: {error}')
Extracting Account Information
try:
# Locate the elements containing the desired information
llc_and_account_number = driver.find_element_by_xpath('//div[@id="accountnumber"]').text
original_purchase_amount = driver.find_element_by_xpath('//p[contains(text(), "Series I current holdings total amount")]/span').text
current_value = driver.find_element_by_xpath('//p[contains(text(), "Series I current holdings current value")]/span').text
issue_date = driver.find_element_by_xpath('(//tr[contains(@class, "altrow")]/td)[3]').text
interest_rate = driver.find_element_by_xpath('//td[contains(text(), "%")]').text
# Separate the LLC name and account number
llc_name, account_number = llc_and_account_number.split(':', 1)
llc_name = llc_name.strip().replace("LLC Name: ", "")
account_number = account_number.strip()
# Print the extracted information
print(f"LLC Name: {llc_name}")
print(f"Account Number: {account_number}")
print(f"Original Purchase Amount: {original_purchase_amount}")
print(f"Current Value: {current_value}")
print(f"Issue Date: {issue_date}")
print(f"Interest Rate: {interest_rate}")
# Save the extracted information as new columns for the current row
df.loc[index, 'LLC Name'] = llc_name
df.loc[index, 'Original Purchase Amount'] = original_purchase_amount
df.loc[index, 'Current Value'] = current_value
df.loc[index, 'Issue Date'] = issue_date
df.loc[index, 'Interest Rate'] = interest_rate
except NoSuchElementException:
print(f"Failed to extract ibond information for account {account_number}. Moving to the next account.")
try:
bank_name = driver.find_element_by_xpath('//tr[@class="altrow1"][1]/td[3]/strong').text
routing_number = driver.find_element_by_xpath('//tr[@class="altrow1"][2]/td[3]/strong').text
account_number = driver.find_element_by_xpath('//tr[@class="altrow1"][3]/td[3]/strong').text
names_on_account = driver.find_element_by_xpath('//tr[@class="altrow1"][4]/td[3]/strong').text
account_type = driver.find_element_by_xpath('//tr[@class="altrow1"][5]/td[3]/strong').text
return_code = driver.find_element_by_xpath('//tr[@class="altrow1"][6]/td[3]/strong').text
# Print the extracted information
print("Bank Name:", bank_name)
print("Routing Number:", routing_number)
print("Account Number:", account_number)
print("Name(s) on Account:", names_on_account)
print("Account Type:", account_type)
print("Return Code:", return_code)
# Save the extracted information as new columns for the current row
df.loc[index, 'Bank Name'] = bank_name
df.loc[index, 'Routing Number'] = routing_number
df.loc[index, 'Account Number'] = account_number
df.loc[index, 'Name(s) on Account'] = names_on_account
df.loc[index, 'Account Type'] = account_type
df.loc[index, 'Return Code'] = return_code
except NoSuchElementException:
print(f"Failed to extract information for account {account_number}. Moving to the next account.")
Full Code:
Coming soon.