
Recently, I needed real-time updates for a court case affecting a house I was purchasing. Instead of constantly checking the case manually, I wrote a Python script to automate this process. The script monitors court case information, party details, case documents, and the case calendar. Whenever it detects an update, it sends an email notification.
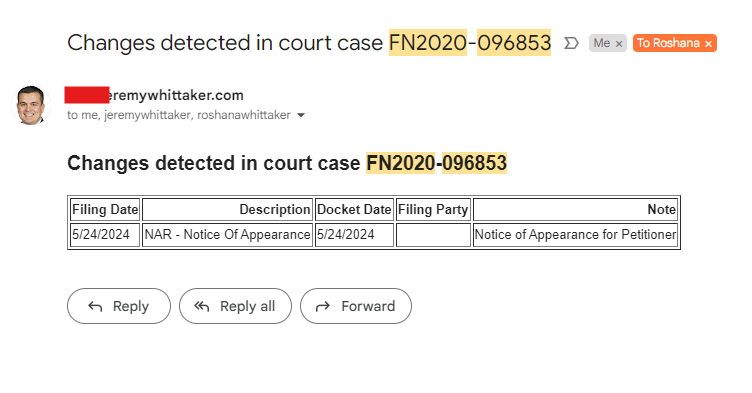
How It Works
The script downloads the latest court case information and saves it to the ./data/ directory in the following CSV formats:
{case_number}_case_information.csv{case_number}_party_information.csv{case_number}_case_documents.csv{case_number}_case_calendar.csv
If there are new updates, it emails the specific rows with the changes.
{case_number}_case_information.csv
{case_number}_party_information.csv
{case_number}_case_documents.csv
{case_number}_case_calendar.csv
Gmail JSON file
To send emails, you need a JSON file to access your Gmail account. Follow these steps:
- Go to the Google Cloud Console:
- Visit Google Cloud Console.
- If you haven’t already, sign in with your Google account.
- Create a New Project (if you don’t already have one):
- Click on the project dropdown at the top and select “New Project.”
- Enter a name for your project and click “Create.”
- Enable the Gmail API:
- In the Google Cloud Console, go to the “APIs & Services” dashboard.
- Click on “Enable APIs and Services.”
- Search for “Gmail API” and click on it.
- Click “Enable” to enable the Gmail API for your project.
- Create Credentials:
- Go to the “Credentials” tab on the left sidebar.
- Click on “Create Credentials” and select “OAuth 2.0 Client ID.”
- You may be prompted to configure the OAuth consent screen. If so, follow the instructions to set up the consent screen (you can fill in minimal information for internal use).
- Choose “Desktop app” for the application type and give it a name.
- Click “Create.”
- Download the JSON File:
- After creating the credentials, you will see a section with your newly created OAuth 2.0 Client ID.
- Click the “Download” button to download the JSON file containing your client secrets.
- Rename this file to
credentials.jsonand place it in the same directory as your script or specify the correct path in your script.
Code
import os
import pickle
import base64
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.auth.transport.requests import Request
import requests
from bs4 import BeautifulSoup
import logging
import csv
import pandas as pd
from email.mime.text import MIMEText
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
# If modifying these SCOPES, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/gmail.send']
def get_credentials():
creds = None
if os.path.exists('/home/shared/algos/monitor_court_case/token.pickle'):
with open('/home/shared/algos/monitor_court_case/token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
try:
creds.refresh(Request())
except Exception as e:
if os.path.exists('/home/shared/algos/monitor_court_case/token.pickle'):
os.remove('/home/shared/algos/monitor_court_case/token.pickle')
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('/home/shared/algos/monitor_court_case/token.pickle', 'wb') as token:
pickle.dump(creds, token)
return creds
def send_email(subject, body, recipients):
creds = get_credentials()
service = build('gmail', 'v1', credentials=creds)
to_addresses = ", ".join(recipients)
message = {
'raw': base64.urlsafe_b64encode(
f"From: me\nTo: {to_addresses}\nSubject: {subject}\nContent-Type: text/html; charset=UTF-8\n\n{body}".encode(
"utf-8")).decode("utf-8")
}
try:
message = (service.users().messages().send(userId="me", body=message).execute())
logging.info(f"Message Id: {message['id']}")
return message
except HttpError as error:
logging.error(f'An error occurred: {error}')
return None
def create_html_table(df):
return df.to_html(index=False)
def fetch_webpage(url):
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
return soup
def parse_case_information(soup):
div = soup.find('div', id='tblForms')
rows = []
if div:
headers = ["Case Number", "Judge", "File Date", "Location", "Case Type"]
rows.append(headers)
case_info = {}
data_divs = div.find_all('div', class_='row g-0 py-0')
for data_div in data_divs:
key_elements = data_div.find_all('div', class_='col-4 col-lg-3 bold-font')
value_elements = data_div.find_all('div', class_='col-8 col-lg-3')
for key_elem, value_elem in zip(key_elements, value_elements):
key = key_elem.get_text(strip=True).replace(':', '')
value = value_elem.get_text(strip=True)
case_info[key] = value
rows.append([
case_info.get("Case Number", ""),
case_info.get("Judge", ""),
case_info.get("File Date", ""),
case_info.get("Location", ""),
case_info.get("Case Type", "")
])
return rows
def parse_party_information(soup):
div = soup.find('div', class_='zebraRowTable grid-um')
rows = []
if div:
headers = ["Party Name", "Relationship", "Sex", "Attorney"]
rows.append(headers)
data_divs = div.find_all('div', class_='row g-0 pt-3 pb-3', id='tblForms2')
for data_div in data_divs:
party_name = data_div.find('div', class_='col-8 col-lg-4').get_text(strip=True)
relationship = data_div.find('div', class_='col-8 col-lg-3').get_text(strip=True)
sex = data_div.find('div', class_='col-8 col-lg-2').get_text(strip=True)
attorney = data_div.find('div', class_='col-8 col-lg-3').get_text(strip=True)
cols = [party_name, relationship, sex, attorney]
logging.debug(f"Parsed row: {cols}")
rows.append(cols)
return rows
def parse_case_documents(soup):
div = soup.find('div', id='tblForms3')
rows = []
if div:
headers = ["Filing Date", "Description", "Docket Date", "Filing Party", "Note"]
rows.append(headers)
data_divs = div.find_all('div', class_='row g-0')
for data_div in data_divs:
cols = [col.get_text(strip=True) for col in
data_div.find_all('div', class_=['col-lg-2', 'col-lg-5', 'col-lg-3'])]
note_text = ""
note_div = data_div.find('div', class_='col-8 pl-3 emphasis')
if note_div:
note_text = note_div.get_text(strip=True).replace("NOTE:", "").strip()
if len(cols) >= 5:
cols[4] = note_text # Update the existing 5th column (Note)
else:
cols.append(note_text) # Append note text if columns are less than 5
if any(cols):
rows.append(cols)
return rows
def parse_case_calendar(soup):
div = soup.find('div', id='tblForms4')
rows = []
if div:
headers = ["Date", "Time", "Event"]
rows.append(headers)
data_divs = div.find_all('div', class_='row g-0')
current_row = []
for data_div in data_divs:
cols = [col.get_text(strip=True) for col in data_div.find_all('div', class_=['col-lg-2', 'col-lg-8'])]
if cols:
current_row.extend(cols)
if len(current_row) == 3:
rows.append(current_row)
current_row = []
return rows
def save_table_to_csv(table, csv_filename):
if table:
with open(csv_filename, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for row in table:
writer.writerow(row)
logging.info(f"Table saved to {csv_filename}")
else:
logging.warning(f"No data found to save in {csv_filename}")
def compare_dates_and_save_table(new_table, csv_filename, date_column, recipients):
if not os.path.exists(csv_filename):
logging.info(f"{csv_filename} does not exist. Creating new file.")
save_table_to_csv(new_table, csv_filename)
return
old_table_df = pd.read_csv(csv_filename)
new_table_df = pd.DataFrame(new_table[1:], columns=new_table[0])
old_dates = set(old_table_df[date_column])
new_dates = set(new_table_df[date_column])
new_rows = new_table_df[new_table_df[date_column].isin(new_dates - old_dates)]
if not new_rows.empty:
logging.info(f"Changes detected in {csv_filename}. Updating file.")
logging.info(f'Here are the new rows \n {new_rows} \n Here is the new table \n {new_table_df}')
logging.info(f"New rows:\n{new_rows.to_string(index=False)}")
html_table = create_html_table(new_rows)
email_body = f"""
<h2>Changes detected in court case {case_number}</h2>
{html_table}
"""
send_email(f"Changes detected in court case {case_number}", email_body, recipients)
save_table_to_csv(new_table, csv_filename)
else:
logging.info(f"No changes detected in {csv_filename}")
if __name__ == "__main__":
case_number = 'FN2020-096853'
url = f"https://www.superiorcourt.maricopa.gov/docket/FamilyCourtCases/caseInfo.asp?caseNumber={case_number}"
data_dir = './data'
os.makedirs(data_dir, exist_ok=True)
recipients = ['email@email.com', 'email@email.com', 'email@email.com'] # Add the recipient email addresses here
soup = fetch_webpage(url)
case_information_table = parse_case_information(soup)
party_information_table = parse_party_information(soup)
case_documents_table = parse_case_documents(soup)
case_calendar_table = parse_case_calendar(soup)
save_table_to_csv(case_information_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_case_information.csv"))
save_table_to_csv(party_information_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_party_information.csv"))
compare_dates_and_save_table(case_documents_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_case_documents.csv"), "Filing Date", recipients)
compare_dates_and_save_table(case_calendar_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_case_calendar.csv"), "Date", recipients)