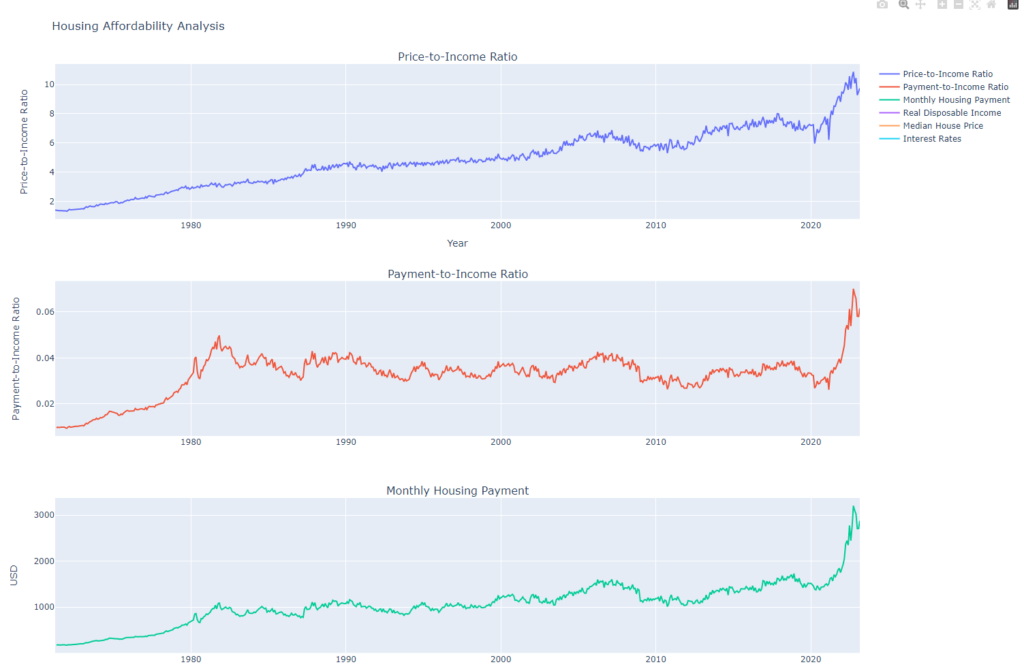
Understanding trends in housing affordability provides crucial insights into financial stability and economic conditions. A key metric to consider is the price-to-payment-to-income ratio. This ratio calculates the burden of mortgage payments on the available income. Over recent years, this ratio has been skyrocketing, indicating a growing financial burden on homeowners. The high price-to-payment-to-income ratio is a clear sign of housing unaffordability, and it suggests that the current state of housing is unsustainable.
Equally concerning is the high price-to-income ratio. This ratio measures the relative cost of housing to available income. When the price-to-income ratio is high, it means that a larger proportion of a person’s income is needed to afford housing.
Given these metrics, it’s clear that something has to give. There are three main possibilities: the Federal Reserve could lower rates, housing prices will fall, or incomes would have to rise dramatically. Each of these scenarios carries its own set of implications and potential problems.
If the Federal Reserve decides to lower rates, it could stimulate economic activity by making borrowing cheaper. However, this could also lead to inflation which the FED has clearly signaled they will fight tooth and nail. Even if rates were to drop, the price-to-income ratio would still remain high as rates have no impact on this directly.
A surge in income is a possibility. While it’s the most ideal, it’s also the least likely. Income growth has been stagnant for many years and it would take a substantial economic shift for incomes to rise dramatically enough to offset the high housing prices. Furthermore, such a change could also lead to inflation, which would, in turn, would cause the FED to continue raising rates.
The current trends suggest that a stagnation or decline in housing prices appears to be the most probable outcome. Many homeowners have secured mortgages with low interest rates, a factor that often leads to less mobility in the housing market as people are less inclined to sell or buy. As a result, we could see a period of low housing turnover stretching out for years into the future.
Housing affordability is a critical issue that affects millions of individuals and families. Understanding trends in housing affordability can provide insights into financial stability, economic conditions, and policy impacts. This article presents a Python script that utilizes public data from the Federal Reserve Economic Data (FRED) API to analyze housing affordability trends. The script retrieves and processes data, calculates key metrics, and presents the results in a clear and interpretable format.
The Python Code
My Python script leverages several libraries – including requests, pandas, and plotly – to fetch, process, and visualize the data. We fetch three key datasets from the FRED API: the median sales price of houses sold in the U.S., real disposable personal income, and the average mortgage interest rate. These three variables are the core components of our housing affordability analysis.
Here’s an overview of how the script works:
Data Retrieval: The get_data function fetches data from the FRED API. It takes a series ID as input and returns a pandas DataFrame containing the data series.
Metric Calculation: We calculate two key ratios to assess housing affordability. The first is the ‘Price-to-Income Ratio’, which is the median house price divided by the real disposable personal income. This ratio measures the relative cost of housing to available income. The second ratio is the ‘Payment-to-Income Ratio’, computed as the monthly mortgage payment divided by the real disposable personal income. This ratio measures the burden of mortgage payments on the available income.
Data Visualization: We use plotly to create an interactive line chart showing these two ratios over time. We also plot the raw values of median house price and real disposable personal income for reference.
Understanding housing affordability is essential for a broad range of applications, from personal finance to macroeconomic policy. With Python and public data APIs, we can create powerful tools to analyze and understand these complex trends.
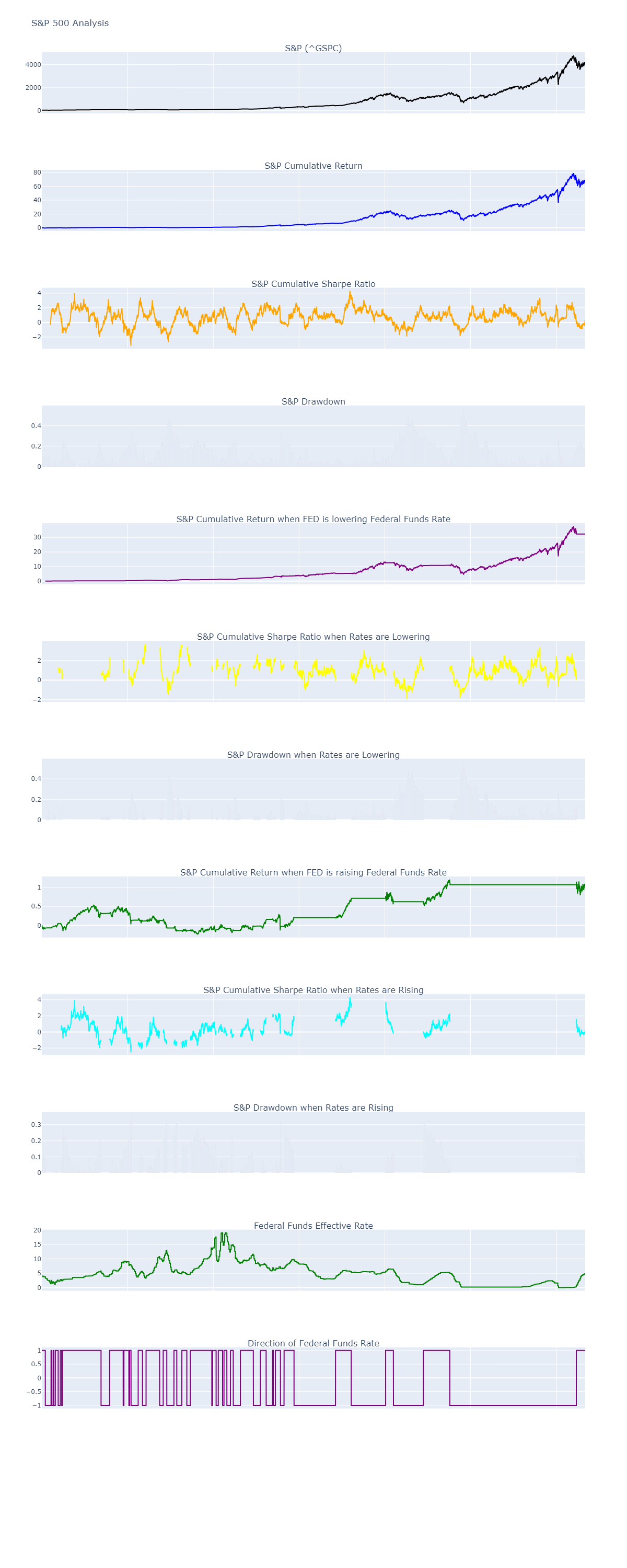
I wanted to analyze the relationship between the Federal Reserve’s (Fed) raising or lowering of interest rates and its impact on the S&P 500 and the median house price. I wrote Python code that fetches data from the St. Louis Fed’s FRED API, processes it, and performs various calculations and visualizations.
Here is the S&P 500 output:
Here is the median house price output:
To begin, I imported the necessary libraries such as requests, pandas, numpy, yfinance, and plotly. These libraries provide functions and tools for data retrieval, manipulation, analysis, and visualization.
The first part of the code focuses on fetching and processing the data related to the Federal Funds Rate (federal_funds_rate_id) and the S&P 500 Index (sp500_id). The get_data function retrieves the Federal Funds Rate data from the FRED API and returns a DataFrame. It processes the data by rounding the rate to the tenth of a percent, creating a new index that extends up to the current date, and filling any missing values with the previous value.
Similarly, the get_sp500_data function uses the Yahoo Finance library (yfinance) to download the historical data of the S&P 500 Total Return Index. It returns a DataFrame containing the adjusted closing prices of the index.
Next, the compute_direction function calculates the direction of the Federal Funds Rate based on the changes in its values. It adds a ‘direction’ column to the DataFrame, where 1 represents an increasing rate, -1 represents a decreasing rate, and 0 represents no change. The function also computes the cumulative difference in rates.
The compute_returns function calculates the daily returns and cumulative returns of the S&P 500 based on the adjusted closing prices. It adds ‘daily_return’, ‘cumulative_return’, ‘cumulative_return_up’, and ‘cumulative_return_down’ columns to the DataFrame. The ‘cumulative_return_up’ and ‘cumulative_return_down’ columns represent the cumulative returns when the Federal Funds Rate is increasing and decreasing, respectively. The function fills any missing values in these columns with the previous value to ensure continuity.
The compute_sharpe_ratio function computes the rolling Sharpe ratios of the S&P 500. It calculates the rolling mean and standard deviation of the daily returns and adds ‘sharpe_ratio_cumulative’, ‘sharpe_ratio_up’, and ‘sharpe_ratio_down’ columns to the DataFrame. The ‘sharpe_ratio_cumulative’ column represents the overall Sharpe ratio, while ‘sharpe_ratio_up’ and ‘sharpe_ratio_down’ represent the Sharpe ratios when the Federal Funds Rate is increasing and decreasing, respectively.
The visualize function generates linked charts using Plotly. It creates a subplot with multiple rows and columns and adds different traces for each chart. The charts include the S&P 500 Index, cumulative returns, cumulative Sharpe ratios, drawdowns, and their respective variations based on the direction of the Federal Funds Rate. The function adjusts the layout properties and displays the charts.
The compute_drawdown function calculates the drawdowns of the S&P 500 based on the maximum value reached by the index. It adds ‘drawdown’, ‘drawdown_up’, and ‘drawdown_down’ columns to the DataFrame. The ‘drawdown’ column represents the overall drawdown, while ‘drawdown_up’ and ‘drawdown_down’ represent the drawdowns when the Federal Funds Rate is increasing and decreasing, respectively.
In the main part of the code, I define the analysis period, fetch the data for the Federal Funds Rate and the S&P 500, and combine them into a single DataFrame. I then compute returns, drawdowns, and Sharpe ratios for the combined data. The DataFrame is saved to a CSV file for further analysis.
Finally, the visualize function is called to generate and display the linked charts for the S&P 500 analysis.
To analyze the relationship between the Federal Funds Rate and the median house price, I modified the code accordingly. I replaced the S&P 500-related functions and variables with their counterparts for the median house price. The get_house_price_data function fetches the data for the median house price, and the visualize function generates the charts specifically for the median house price analysis. The remaining parts of the code remain the same.
In conclusion, this code provides a comprehensive analysis of the relationship between the Federal Funds Rate, the S&P 500, and the median house price. It fetches the necessary data, performs calculations, and generates visualizations to gain insights into the impact of interest rate changes on these economic indicators. The code can be customized and extended for further analysis or applied to other datasets of interest.
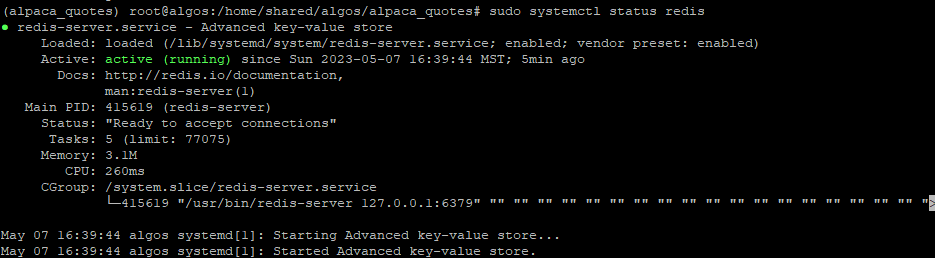
Like many brokers, you don’t get to make unlimited connections to the Alpaca API. What I’m going to set up today is Redis to redistribute Alpaca trades, quotes, and bars data. The purpose of this is so that all of my algorithms have access to Alpaca’s data.
This program also shows you how many symbols are missing each minute, saves the data to dataframes and to your local disk for further analysis.
main.py: This is the entry point of the application, responsible for initializing the subscription and handling user input.
redis_subscriber.py: This file establishes a connection to Redis and sets up the subscription mechanism for Alpaca trades, quotes, or bars. It listens for incoming data and then broadcasts it to the appropriate channels for further processing.
subscriptions.py: This file contains functions for subscribing and unsubscribing to Alpaca trades, quotes, and bars. These functions ensure a smooth and error-free data streaming experience.
message_processing.py: This file processes incoming data from the Alpaca API and formats it for further analysis. It handles any errors that may occur during the process and ensures that the data is consistent and accurate.
dataframes.py: This file manages the dataframes used for storing and analyzing the received data. It organizes the data in an accessible format and performs any necessary data manipulation tasks.
config.py: This file manages the configuration, including API keys, directory settings, and the Alpaca REST API instance. Centralizing these configurations ensures easy maintenance and organization.
If you successfully get a PONG reply after issuing this command Redis is now configured. You should only run Redis in this set up on a secure internal network. Further hardening is required if this network is accessible.
main.py
import asyncio
import websockets
import json
import os
import traceback
from colorama import Fore, Style, init
import redis
from config import APCA_API_KEY_ID, APCA_API_SECRET_KEY, live_api
from subscriptions import subscribe_to_trades, subscribe_to_quotes, subscribe_to_bars,\
unsubscribe_trade_updates, unsubscribe_quote_updates, unsubscribe_bar_updates
from message_processing import process_message
import websockets.exceptions
import pandas as pd
from datetime import datetime
from dataframes import create_dataframes
symbols_to_trade = []
async def on_message(ws, message):
try:
messages = json.loads(message)
for msg in messages:
process_message(msg, trades_df, quotes_df, bars_df)
redis_client.publish('alpaca-messages', json.dumps(msg))
except Exception as e:
print("Error in on_message:")
traceback.print_exc()
async def authenticate(ws):
auth_data = {
"action": "auth",
"key": APCA_API_KEY_ID,
"secret": APCA_API_SECRET_KEY
}
await ws.send(json.dumps(auth_data))
async def create_ws_connection(symbols, source='sip'):
base_url = f'wss://stream.data.alpaca.markets/v2/{source}'
async with websockets.connect(base_url, ping_timeout=60) as ws: # Set ping_timeout to 60 seconds
await authenticate(ws)
# Subscribe to trades
print('Subscribing to trades')
await subscribe_to_trades(ws, symbols_to_trade)
# Subscribe to quotes
print('Subscribing to quotes')
await subscribe_to_quotes(ws, symbols_to_trade)
# Subscribe to bars
print('Subscribing to bars')
await subscribe_to_bars(ws, symbols_to_trade)
while True:
try:
message = await ws.recv()
await on_message(ws, message)
except websockets.exceptions.ConnectionClosedError as e:
print(f"Connection closed: {e}, reconnecting...")
await create_ws_connection(symbols_to_trade, source=source)
break
except Exception as e:
print(f"Error: {e}")
def get_assets(active=True, tradable=False, shortable=False, exclude_curencies=True):
global symbols_to_trade
assets = live_api.list_assets()
filtered_assets_dict = {}
for asset in assets:
if active and asset.status != 'active':
continue
if tradable and not asset.tradable:
continue
if shortable and not asset.shortable:
continue
if exclude_curencies and '/' in asset.symbol:
continue
filtered_assets_dict[asset.symbol] = asset.name
symbols_to_trade = list(filtered_assets_dict.keys())
print(f'Returning {len(symbols_to_trade)} assets')
return symbols_to_trade
async def run_stream(symbols_to_trade, source='sip'):
while True:
try:
await create_ws_connection(symbols_to_trade, source=source)
except websockets.exceptions.ConnectionClosedError as e:
print(f"Connection closed: {e}, retrying in 1 seconds...")
await asyncio.sleep(1)
except Exception as e:
print(f"Error: {e}, retrying in 1 seconds...")
await asyncio.sleep(1)
if __name__ == "__main__":
symbols = get_assets(active=True, tradable=False, shortable=False, exclude_curencies=True)
trades_df, quotes_df, bars_df = create_dataframes(symbols)
redis_client = redis.Redis(host='localhost', port=6379, db=0)
asyncio.run(run_stream(symbols_to_trade))
redis_subscriber.py
import redis
def on_message(channel, message):
print(f"Message received on channel '{channel}': {message}")
def main():
redis_client = redis.Redis(host='localhost', port=6379, decode_responses=True)
# Replace 'alpaca-messages' with the desired channel name
channel_name = 'alpaca-messages'
pubsub = redis_client.pubsub()
pubsub.subscribe(channel_name)
print(f"Subscribed to '{channel_name}' channel. Awaiting messages...")
while True:
message = pubsub.get_message()
if message:
if message['type'] == 'message':
on_message(message['channel'], message['data'])
if __name__ == "__main__":
main()
dataframes.py
import pandas as pd
import traceback
from datetime import datetime
from dateutil.parser import parse
import pytz
import os
from config import minute_data_dir
import asyncio
tzinfos = {'ZZ': pytz.UTC}
def append_to_csv(file_path, data):
with open(file_path, 'a') as f:
f.write(data + '\n')
def check_missing_values():
while True:
time.sleep(60) # Wait for 1 minute
for df_name, df in zip(["trades_df", "quotes_df", "bars_df"], [trades_df, quotes_df, bars_df]):
row_missing_percentage = (df.isna().sum(axis=1) / df.shape[1] * 100).round(2)
print(f"{df_name} row missing values (%):\n{row_missing_percentage}\n")
def create_dataframes(symbols):
global trades_df, quotes_df, bars_df
trades_columns = pd.MultiIndex.from_product([symbols, ['price', 'size', 'timestamp']])
quotes_columns = pd.MultiIndex.from_product([symbols, ['bid', 'ask']])
bars_columns = pd.MultiIndex.from_product([symbols, ['open', 'high', 'low', 'close', 'volume']])
trades_df = pd.DataFrame(columns=trades_columns)
quotes_df = pd.DataFrame(columns=quotes_columns)
bars_df = pd.DataFrame(columns=bars_columns)
return trades_df, quotes_df, bars_df
#
# async def save_data(df, data_directory, file_name, file_format='pickle'):
# #CSV saving does not currently work as it slows down the process and the wss will die.
# if not os.path.exists(data_directory):
# os.makedirs(data_directory)
#
# file_path = os.path.join(data_directory, f"{file_name}.{file_format}")
#
# # Calculate missing data percentage for the row to be appended
# row_missing_percentage = (df.isna().sum(axis=1) / df.shape[1] * 100).round(2)
# print(f"{file_name} row missing values (%):\n{row_missing_percentage}\n")
#
# if not os.path.exists(file_path):
# if file_format == 'csv':
# with open(file_path, 'w') as f:
# f.write(df.to_csv(header=True, index=True))
# elif file_format == 'pickle':
# df.to_pickle(file_path)
# else:
# if file_format == 'csv':
# existing_df = pd.read_csv(file_path, header=[0, 1], index_col=0)
# combined_df = pd.concat([existing_df, df])
# # Ensure the correct column order in the combined DataFrame
# combined_df = combined_df.reorder_levels([1, 0], axis=1).sort_index(axis=1)
#
# with open(file_path, 'w') as f:
# f.write(combined_df.to_csv(header=True, index=True))
# elif file_format == 'pickle':
# existing_df = pd.read_pickle(file_path)
# combined_df = pd.concat([existing_df, df])
# combined_df.to_pickle(file_path)
def update_trades_df(symbol, price, size, timestamp, df, minute_data_dir):
try:
timestamp_dt = parse(timestamp, tzinfos=tzinfos).replace(second=0, microsecond=0)
if timestamp_dt not in df.index:
# if len(df.index) > 1:
# asyncio.create_task(save_data(df, minute_data_dir, 'trades', 'pickle'))
df.loc[timestamp_dt] = pd.Series(dtype='float64')
df.at[timestamp_dt, (symbol, 'price')] = price
# Cumulatively add 1 size to the current size value
current_size = df.at[timestamp_dt, (symbol, 'size')]
if pd.isna(current_size):
current_size = 0
df.at[timestamp_dt, (symbol, 'size')] = current_size + size
except Exception as e:
print("Error:", e)
traceback.print_exc()
def update_quotes_df(symbol, bid, ask, timestamp, df, minute_data_dir):
try:
timestamp_dt = parse(timestamp, tzinfos=tzinfos).replace(second=0, microsecond=0)
if timestamp_dt not in df.index:
# if len(df.index) > 1:
# asyncio.create_task(save_data(df, minute_data_dir, "quotes", 'pickle'))
df.loc[timestamp_dt] = pd.Series(dtype='float64')
df.at[timestamp_dt, (symbol, 'bid')] = bid
df.at[timestamp_dt, (symbol, 'ask')] = ask
except Exception as e:
print("Error:", e)
traceback.print_exc()
def update_bars_df(symbol, open_price, high_price, low_price, close_price, volume, timestamp, df, minute_data_dir):
try:
timestamp_dt = datetime.fromisoformat(timestamp.replace('Z', '+00:00')).replace(second=0, microsecond=0)
if timestamp_dt not in df.index:
# if len(df.index) > 1:
# asyncio.create_task(save_data(df, minute_data_dir, "bars", 'pickle'))
df.loc[timestamp_dt] = pd.Series(dtype='float64')
df.at[timestamp_dt, (symbol, 'open')] = open_price
df.at[timestamp_dt, (symbol, 'high')] = high_price
df.at[timestamp_dt, (symbol, 'low')] = low_price
df.at[timestamp_dt, (symbol, 'close')] = close_price
df.at[timestamp_dt, (symbol, 'volume')] = volume
except Exception as e:
print("Error:", e)
traceback.print_exc()
import os
import sys
import alpaca_trade_api as tradeapi
parent_dir = os.path.abspath(os.path.join(os.getcwd(), '..'))
data_dir = os.path.join(parent_dir, 'data/')
sys.path.append(data_dir)
minute_data_dir = os.path.join(data_dir, 'minute_data/')
import keys
BASE_URL, API_KEY, SECRET_KEY = #define your own here
LIVE_BASE_URL, LIVE_API_KEY, LIVE_SECRET_KEY = #define your own here
LIVE_BASE_URL, APCA_API_KEY_ID, APCA_API_SECRET_KEY = #define your own here
live_api = tradeapi.REST(LIVE_API_KEY, LIVE_SECRET_KEY, LIVE_BASE_URL, api_version='v2')
The world of finance and trading has seen a massive surge in the use of technology and data. With the increasing availability of APIs and data streams, it has become essential for traders and developers to harness the power of real-time information to make better-informed decisions. Alpaca, a popular commission-free trading API, is one such service that enables developers to access real-time market data and automate their trading strategies.
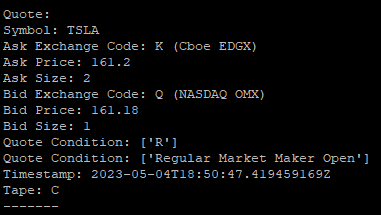
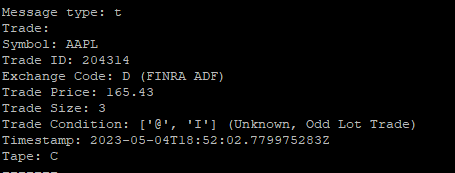
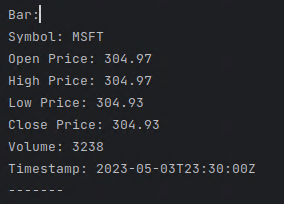
However, getting started with Alpaca’s API and handling WebSocket streams for quotes, trades, and bars can be a challenging task, especially for those who are new to the domain. To help you overcome this hurdle, I have put together a Python template that simplifies the process and serves as a starting point for your custom trading projects. Here is a sample of the outputs.
Quotes:
Trades:
Bars:
In this blog post, I will walk you through the key components of this template, and explain how you can use it to access real-time data from Alpaca’s API and modify it according to your preferences.
Organizing the Codebase
The first step towards building a clean and maintainable trading application is to organize your codebase into modular components. In our template, we have separated the code into different modules:
config.py: Contains the API key and secret key for Alpaca authentication.
constants.py: Stores dictionaries for exchange codes, trade conditions, and quote conditions.
subscriptions.py: Defines functions for subscribing and unsubscribing from trades, quotes, and bars.
message_processing.py: Contains a function for processing incoming messages from the WebSocket stream.
By organizing the code in this manner, we can easily manage and extend our trading application as needed.
Establishing a WebSocket Connection
Our template uses the websocket library to establish a connection with Alpaca’s WebSocket stream. This is done in the create_ws_connection function, which takes the list of symbols and the data source (either ‘sip’ or ‘iex’) as input, and returns a WebSocketApp object. This object is then used to authenticate, subscribe, and handle incoming messages.
Authenticating with Alpaca’s API
Before you can access real-time market data from Alpaca, you need to authenticate your WebSocket connection. The authenticate function sends an authentication message to the WebSocket, which includes your API key and secret key. Once authenticated, you can subscribe to various data streams.
Subscribing to Real-time Data
Our template provides functions for subscribing to trades, quotes, and bars: subscribe_to_trades, subscribe_to_quotes, and subscribe_to_bars. These functions send subscription messages to the WebSocket, specifying the symbols you want to receive updates for.
You can also unsubscribe from any data stream using the corresponding unsubscribe_* functions, such as unsubscribe_trade_updates.
Processing Incoming Messages
The on_message function handles incoming messages from the WebSocket stream. It parses the message and delegates the processing to the process_message function, which is defined in the message_processing.py module. This function takes care of processing trade, quote, and bar messages, as well as handling any errors or subscription updates.
This Python template serves as a solid foundation for building custom trading applications using Alpaca’s API. It simplifies the process of connecting to the WebSocket, authenticating, subscribing to data streams, and processing incoming messages. By using this template as a starting point, you can focus on implementing your trading strategies and refining your application according to your needs.
Feel free to modify and extend the code as required, and embark on your journey of harnessing the power of real-time market data to create sophisticated trading algorithms and applications.
In the future, you may consider incorporating features such as order management, portfolio tracking, and risk management to further enhance your trading application. Additionally, you can explore integrating other data sources and APIs to complement Alpaca’s data and provide a more comprehensive view of the market.
By leveraging this Alpaca Subscribe Template, you can quickly dive into the world of algorithmic trading and capitalize on the opportunities provided by real-time market data. So go ahead, experiment with the code, and unleash the potential of data-driven trading strategies for better decision-making and profitability. Happy coding!
main.py
import websocket
import json
import threading
import time
import os
from colorama import Fore, Style, init
from config import APCA_API_KEY_ID, APCA_API_SECRET_KEY
from constants import exchange_codes, trade_conditions_cts, cqs_quote_conditions, uqdf_quote_conditions
from subscriptions import subscribe_to_trades, subscribe_to_quotes, subscribe_to_bars,\
unsubscribe_trade_updates, unsubscribe_quote_updates, unsubscribe_bar_updates
from message_processing import process_message
# Function to handle incoming messages
def on_message(ws, message):
# print("Message received: " + message)
messages = json.loads(message)
for msg in messages:
process_message(msg)
# Function to authenticate
def authenticate(ws):
auth_data = {
"action": "auth",
"key": APCA_API_KEY_ID,
"secret": APCA_API_SECRET_KEY
}
ws.send(json.dumps(auth_data))
# Function to subscribe to trades
def create_ws_connection(symbols, source='sip'):
base_url = f'wss://stream.data.alpaca.markets/v2/{source}'
ws = websocket.WebSocketApp(
base_url,
on_message=on_message
)
# Authenticate and subscribe when the connection is open
ws.on_open = lambda ws: authenticate(ws)
return ws
if __name__ == "__main__":
# List of symbols to subscribe
symbols = ["AAPL", "MSFT", "GOOG", "FB", "AMZN", "TSLA", "NFLX", "NVDA", "AMD", "TWTR", "SNAP"]
# Source: 'sip' or 'iex'
source = 'sip'
# Create a connection to the WebSocket
ws = create_ws_connection(symbols, source=source)
# Start the WebSocket connection in a new thread
ws_thread = threading.Thread(target=ws.run_forever)
ws_thread.start()
time.sleep(5)
# Let the WebSocket run for a while to receive updates
# Subscribe to trades
print('Subscribing to trades')
subscribe_to_trades(ws, symbols)
# unsubscribe_trade_updates(ws, symbols)
# Subscribe to quotes
print('Subscribing to quotes')
subscribe_to_quotes(ws, symbols)
# unsubscribe_quote_updates(ws, symbols)
# Subscribe to bars
print('Subscribing to bars')
# subscribe_to_bars(ws, symbols)
# time.sleep(5)
# unsubscribe_bar_updates(ws, symbols)