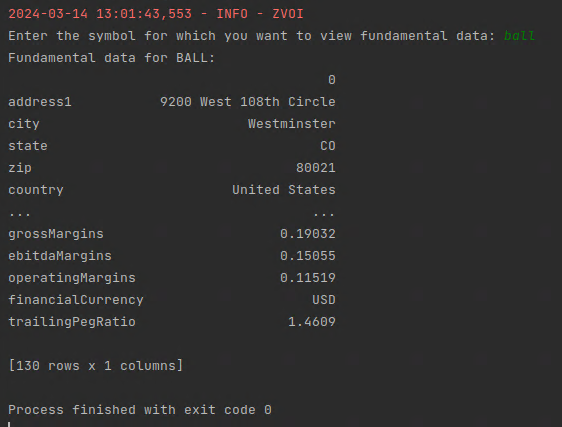
Fundamental data offers a plethora of data points about a company’s financial health and market position. I want to share a streamlined approach to accessing and storing fundamental data for a wide array of stocks using yfinance, a powerful tool that offers free access to financial data.
This Python code leverages yfinance to download fundamental data for stocks and store it in an HDF5 file. This approach not only ensures quick access to a vast array of fundamental data but also organizes it in a structured, easily retrievable manner.
The code is structured into two main functions: save_fundamental_data and download_and_save_symbols. Here’s a breakdown of their functionality:
save_fundamental_data: This function serves as the entry point. It checks for the existence of an HDF5 file that serves as our data repository. If the file doesn’t exist, it’s created during the first run. The function then identifies which symbols need their data downloaded and saved, distinguishing between those not yet present in the file and those requiring updates.
download_and_save_symbols: As the workhorse of our code, this function iterates through the list of symbols, fetching their fundamental data fromyfinanceand handling any special cases, such as columns that need renaming due to naming convention conflicts. It employs a retry logic to ensure reliability even in the face of temporary network issues or API limitations.
The entire process is designed to be incremental, meaning it prioritizes adding new symbols to the HDF5 file before updating existing entries. This approach optimizes the use of network resources and processing time.
Hurdles
Throughout the development process, I encountered several interesting challenges, notably:
- Naming Convention Conflicts: PyTables, the underlying library used for handling HDF5 files in Python, imposes strict naming conventions that caused issues with certain column names returned by
yfinance(e.g.,52WeekChange). To circumvent this, the code includes logic to rename problematic columns, ensuring compatibility with PyTables. - Serialization Issues: Some columns contain complex data types that need special handling before they can be stored in HDF5 format. The code serializes these columns, converting them into a format suitable for storage.
- Retry Logic for Robustness: Network unreliability and API rate limiting can disrupt data download processes. Implementing a retry mechanism significantly improves the robustness of our data fetching routine, making our script more reliable.
Functions to Create and Save Data
def save_fundamental_data(symbols=None):
"""
Incrementally save fundamental data for a list of stock symbols to an HDF file.
Prioritizes saving data for symbols not already present in the file before updating existing entries.
Args:
symbols (list, optional): List of stock symbols. Defaults to None, meaning it will fetch active assets.
Returns:
None
"""
hdf_file_path = '/home/shared/algos/data/fundamental_data.h5'
existing_symbols = set()
download_failures = []
# Check if the HDF5 file exists before attempting to read existing symbols
if os.path.exists(hdf_file_path):
with pd.HDFStore(hdf_file_path, mode='r') as store:
existing_symbols = set(store.keys())
existing_symbols = {symbol.strip('/') for symbol in existing_symbols} # Remove leading slashes
else:
logging.info("HDF5 file does not exist. It will be created on the first write operation.")
if symbols is None:
symbols = list(get_active_assets().keys())
symbols = [s.replace('.', '-') for s in symbols]
# Separate symbols into those that need to be added and those that need updating
symbols_to_add = [symbol for symbol in symbols if symbol not in existing_symbols]
symbols_to_update = [symbol for symbol in symbols if symbol in existing_symbols]
# Download and save data for symbols not already in the HDF5 file
download_and_save_symbols(symbols_to_add, hdf_file_path, download_failures, "Adding new symbols")
# Update data for symbols already in the HDF5 file
download_and_save_symbols(symbols_to_update, hdf_file_path, download_failures, "Updating existing symbols")
if download_failures:
logging.info(f"Failed to download data for the following symbols: {', '.join(download_failures)}")
logging.info("All fundamental data processing attempted.")
def download_and_save_symbols(symbols, hdf_file_path, download_failures, description):
"""
Helper function to download and save fundamental data for a list of symbols.
Args:
symbols (list): List of symbols to process.
hdf_file_path (str): Path to the HDF5 file.
download_failures (list): List to track symbols that failed to download.
description (str): Description of the current process phase.
Returns:
None
"""
max_retries = 5
retry_delay = 5
for symbol in tqdm(symbols, desc="Processing symbols"):
try:
stock = yf.Ticker(symbol)
info = stock.info
# Special handling for 'companyOfficers' column if it's causing serialization issues
if 'companyOfficers' in info and isinstance(info['companyOfficers'], (list, dict)):
info['companyOfficers'] = json.dumps(info['companyOfficers'])
info_df = pd.DataFrame([info])
if '52WeekChange' in info_df.columns:
info_df = info_df.rename(columns={'52WeekChange': 'WeekChange_52'})
if 'yield' in info_df.columns:
info_df = info_df.rename(columns={'yield': 'yield_value'})
except Exception as e:
logging.warning(f"Failed to download data for {symbol}: {e}")
download_failures.append(symbol)
continue # Skip to the next symbol
# Attempt to save the data to HDF5 with retries for write errors
for attempt in range(max_retries):
try:
with pd.HDFStore(hdf_file_path, mode='a') as store:
store.put(symbol, info_df, format='table', data_columns=True)
logging.info(f"Fundamental data saved for {symbol}")
break # Success, exit retry loop
except Exception as e:
logging.warning(f"Retry {attempt + 1} - Error saving data for {symbol} to HDF: {e}")
if attempt < max_retries - 1:
time.sleep(retry_delay) # Wait before retrying, but not after the last attempt
Run Code
To run this code you will need to provide a list of symbols. In my instance, my symbols are generated from Alpaca API. It queries the API for active assets. Below is that function. But the code can also be run manually like this.
symbols = ['AAPL', 'MSFT'] save_fundamental_data(symbols)
Get Alpaca Active Assets
def get_active_assets():
api = tradeapi.REST(LIVE_API_KEY, LIVE_API_SECRET, LIVE_BASE_URL, api_version='v2')
assets = api.list_assets()
assets_dict = {}
for asset in assets:
if asset.status == 'active':
assets_dict[asset.symbol] = asset.name
return assets_dict
Function to Query Data
def print_fundamental_data():
"""
Access and print the fundamental data for a given stock symbol from an HDF5 file,
ensuring all rows are displayed.
Returns:
None, but prints the fundamental data for the specified symbol if available.
"""
hdf_file_path = '/home/shared/algos/data/fundamental_data.h5'
max_retries = 5
retry_delay = 5
for _ in range(max_retries):
try:
# Open the HDF5 file and retrieve all keys (symbols)
with pd.HDFStore(hdf_file_path, mode='r') as store:
keys = store.keys()
logging.info("Available symbols:")
for key in keys:
logging.info(key[1:]) # Remove leading '/' from symbol name
# Prompt user to choose a symbol
symbol = input("Enter the symbol for which you want to view fundamental data: ").strip().upper()
# Check if the chosen symbol exists in the HDF5 file
with pd.HDFStore(hdf_file_path, mode='r') as store:
if f'/{symbol}' in store:
data_df = store[symbol] # Read the dataframe for the symbol
# Transpose the DataFrame to print all rows without abbreviation
data_df_transposed = data_df.T
# Print all columns without asking for user input
print(f"Fundamental data for {symbol}:")
print(data_df_transposed)
else:
logging.info(f"No data found for symbol: {symbol}")
break # Exit the retry loop if successful
except Exception as e:
logging.error(f"Error accessing HDF5 file: {e}")
logging.info(f"Retrying in {retry_delay} seconds...")
time.sleep(retry_delay)
else:
logging.error("Failed to access HDF5 file after multiple retries.")
# Example usage
print_fundamental_data()