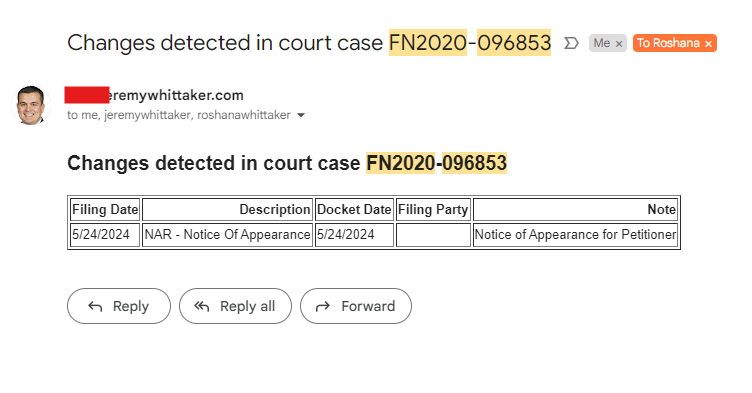
Recently, I needed real-time updates for a court case affecting a house I was purchasing. Instead of constantly checking the case manually, I wrote a Python script to automate this process. The script monitors court case information, party details, case documents, and the case calendar. Whenever it detects an update, it sends an email notification.
How It Works
The script downloads the latest court case information and saves it to the ./data/ directory in the following CSV formats:
{case_number}_case_information.csv
{case_number}_party_information.csv
{case_number}_case_documents.csv
{case_number}_case_calendar.csv
If there are new updates, it emails the specific rows with the changes.
If you haven’t already, sign in with your Google account.
Create a New Project (if you don’t already have one):
Click on the project dropdown at the top and select “New Project.”
Enter a name for your project and click “Create.”
Enable the Gmail API:
In the Google Cloud Console, go to the “APIs & Services” dashboard.
Click on “Enable APIs and Services.”
Search for “Gmail API” and click on it.
Click “Enable” to enable the Gmail API for your project.
Create Credentials:
Go to the “Credentials” tab on the left sidebar.
Click on “Create Credentials” and select “OAuth 2.0 Client ID.”
You may be prompted to configure the OAuth consent screen. If so, follow the instructions to set up the consent screen (you can fill in minimal information for internal use).
Choose “Desktop app” for the application type and give it a name.
Click “Create.”
Download the JSON File:
After creating the credentials, you will see a section with your newly created OAuth 2.0 Client ID.
Click the “Download” button to download the JSON file containing your client secrets.
Rename this file to credentials.json and place it in the same directory as your script or specify the correct path in your script.
Code
import os
import pickle
import base64
from google_auth_oauthlib.flow import InstalledAppFlow
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
from google.auth.transport.requests import Request
import requests
from bs4 import BeautifulSoup
import logging
import csv
import pandas as pd
from email.mime.text import MIMEText
logging.basicConfig(level=logging.DEBUG, format='%(asctime)s - %(levelname)s - %(message)s')
# If modifying these SCOPES, delete the file token.pickle.
SCOPES = ['https://www.googleapis.com/auth/gmail.send']
def get_credentials():
creds = None
if os.path.exists('/home/shared/algos/monitor_court_case/token.pickle'):
with open('/home/shared/algos/monitor_court_case/token.pickle', 'rb') as token:
creds = pickle.load(token)
if not creds or not creds.valid:
if creds and creds.expired and creds.refresh_token:
try:
creds.refresh(Request())
except Exception as e:
if os.path.exists('/home/shared/algos/monitor_court_case/token.pickle'):
os.remove('/home/shared/algos/monitor_court_case/token.pickle')
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
else:
flow = InstalledAppFlow.from_client_secrets_file('credentials.json', SCOPES)
creds = flow.run_local_server(port=0)
with open('/home/shared/algos/monitor_court_case/token.pickle', 'wb') as token:
pickle.dump(creds, token)
return creds
def send_email(subject, body, recipients):
creds = get_credentials()
service = build('gmail', 'v1', credentials=creds)
to_addresses = ", ".join(recipients)
message = {
'raw': base64.urlsafe_b64encode(
f"From: me\nTo: {to_addresses}\nSubject: {subject}\nContent-Type: text/html; charset=UTF-8\n\n{body}".encode(
"utf-8")).decode("utf-8")
}
try:
message = (service.users().messages().send(userId="me", body=message).execute())
logging.info(f"Message Id: {message['id']}")
return message
except HttpError as error:
logging.error(f'An error occurred: {error}')
return None
def create_html_table(df):
return df.to_html(index=False)
def fetch_webpage(url):
response = requests.get(url)
response.raise_for_status()
soup = BeautifulSoup(response.content, 'html.parser')
return soup
def parse_case_information(soup):
div = soup.find('div', id='tblForms')
rows = []
if div:
headers = ["Case Number", "Judge", "File Date", "Location", "Case Type"]
rows.append(headers)
case_info = {}
data_divs = div.find_all('div', class_='row g-0 py-0')
for data_div in data_divs:
key_elements = data_div.find_all('div', class_='col-4 col-lg-3 bold-font')
value_elements = data_div.find_all('div', class_='col-8 col-lg-3')
for key_elem, value_elem in zip(key_elements, value_elements):
key = key_elem.get_text(strip=True).replace(':', '')
value = value_elem.get_text(strip=True)
case_info[key] = value
rows.append([
case_info.get("Case Number", ""),
case_info.get("Judge", ""),
case_info.get("File Date", ""),
case_info.get("Location", ""),
case_info.get("Case Type", "")
])
return rows
def parse_party_information(soup):
div = soup.find('div', class_='zebraRowTable grid-um')
rows = []
if div:
headers = ["Party Name", "Relationship", "Sex", "Attorney"]
rows.append(headers)
data_divs = div.find_all('div', class_='row g-0 pt-3 pb-3', id='tblForms2')
for data_div in data_divs:
party_name = data_div.find('div', class_='col-8 col-lg-4').get_text(strip=True)
relationship = data_div.find('div', class_='col-8 col-lg-3').get_text(strip=True)
sex = data_div.find('div', class_='col-8 col-lg-2').get_text(strip=True)
attorney = data_div.find('div', class_='col-8 col-lg-3').get_text(strip=True)
cols = [party_name, relationship, sex, attorney]
logging.debug(f"Parsed row: {cols}")
rows.append(cols)
return rows
def parse_case_documents(soup):
div = soup.find('div', id='tblForms3')
rows = []
if div:
headers = ["Filing Date", "Description", "Docket Date", "Filing Party", "Note"]
rows.append(headers)
data_divs = div.find_all('div', class_='row g-0')
for data_div in data_divs:
cols = [col.get_text(strip=True) for col in
data_div.find_all('div', class_=['col-lg-2', 'col-lg-5', 'col-lg-3'])]
note_text = ""
note_div = data_div.find('div', class_='col-8 pl-3 emphasis')
if note_div:
note_text = note_div.get_text(strip=True).replace("NOTE:", "").strip()
if len(cols) >= 5:
cols[4] = note_text # Update the existing 5th column (Note)
else:
cols.append(note_text) # Append note text if columns are less than 5
if any(cols):
rows.append(cols)
return rows
def parse_case_calendar(soup):
div = soup.find('div', id='tblForms4')
rows = []
if div:
headers = ["Date", "Time", "Event"]
rows.append(headers)
data_divs = div.find_all('div', class_='row g-0')
current_row = []
for data_div in data_divs:
cols = [col.get_text(strip=True) for col in data_div.find_all('div', class_=['col-lg-2', 'col-lg-8'])]
if cols:
current_row.extend(cols)
if len(current_row) == 3:
rows.append(current_row)
current_row = []
return rows
def save_table_to_csv(table, csv_filename):
if table:
with open(csv_filename, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
for row in table:
writer.writerow(row)
logging.info(f"Table saved to {csv_filename}")
else:
logging.warning(f"No data found to save in {csv_filename}")
def compare_dates_and_save_table(new_table, csv_filename, date_column, recipients):
if not os.path.exists(csv_filename):
logging.info(f"{csv_filename} does not exist. Creating new file.")
save_table_to_csv(new_table, csv_filename)
return
old_table_df = pd.read_csv(csv_filename)
new_table_df = pd.DataFrame(new_table[1:], columns=new_table[0])
old_dates = set(old_table_df[date_column])
new_dates = set(new_table_df[date_column])
new_rows = new_table_df[new_table_df[date_column].isin(new_dates - old_dates)]
if not new_rows.empty:
logging.info(f"Changes detected in {csv_filename}. Updating file.")
logging.info(f'Here are the new rows \n {new_rows} \n Here is the new table \n {new_table_df}')
logging.info(f"New rows:\n{new_rows.to_string(index=False)}")
html_table = create_html_table(new_rows)
email_body = f"""
<h2>Changes detected in court case {case_number}</h2>
{html_table}
"""
send_email(f"Changes detected in court case {case_number}", email_body, recipients)
save_table_to_csv(new_table, csv_filename)
else:
logging.info(f"No changes detected in {csv_filename}")
if __name__ == "__main__":
case_number = 'FN2020-096853'
url = f"https://www.superiorcourt.maricopa.gov/docket/FamilyCourtCases/caseInfo.asp?caseNumber={case_number}"
data_dir = './data'
os.makedirs(data_dir, exist_ok=True)
recipients = ['email@email.com', 'email@email.com', 'email@email.com'] # Add the recipient email addresses here
soup = fetch_webpage(url)
case_information_table = parse_case_information(soup)
party_information_table = parse_party_information(soup)
case_documents_table = parse_case_documents(soup)
case_calendar_table = parse_case_calendar(soup)
save_table_to_csv(case_information_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_case_information.csv"))
save_table_to_csv(party_information_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_party_information.csv"))
compare_dates_and_save_table(case_documents_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_case_documents.csv"), "Filing Date", recipients)
compare_dates_and_save_table(case_calendar_table, os.path.join(data_dir, f"/home/shared/algos/monitor_court_case/data/{case_number}_case_calendar.csv"), "Date", recipients)
The Financial Crimes Enforcement Network (FinCEN) now requires most businesses to report their beneficial owners, a mandate stemming from the U.S. Corporate Transparency Act. The penalties for non-compliance are exceptionally harsh. Anyone willfully violating the reporting requirements could face penalties of up to $500 for each day of continued violation, with criminal penalties including up to two years of imprisonment and fines up to $10,000. All the FAQs for BOIR reporting can be found here.
Fortunately, if you only have a few companies, filling out this form should take no longer than 15 minutes. You can access the online filing system here. However, if you have hundreds of LLCs, this process can quickly become overwhelming, potentially taking days to complete multiple forms. To address this, I’ve developed a code to automate the process. If all your companies have the same beneficial owners, this script will streamline the reporting process. However, you will still need to verify your humanity and the information filled out when you reach the CAPTCHA at the end.
Using Selenium in Python to Navigate FinCEN
These lines need to be modified with your information
last_name_field.send_keys("Last Name")
first_name_field.send_keys("First Name")
dob_field.send_keys("01/01/1982")
address_field.send_keys("Address field")
city_field.send_keys("City")
fill_dropdown(driver, country_field, "United States of America")
fill_dropdown(driver, state_field, "Arizona")
zip_field.send_keys("00000")
id_number_field.send_keys("Drivers license number")
fill_dropdown(driver, id_country_field, "United States of America")
fill_dropdown(driver, id_state_field, "Arizona")
id_file_field.send_keys("/full/path/of/ID.jpeg")
last_name_field_2.send_keys("Beneficial Owner #2 Last Name")
first_name_field_2.send_keys("Beneficial Owner #2 First Name")
dob_field_2.send_keys("Beneficial Owner #2 DOB")
address_field_2.send_keys("Beneficial Owner #2 Address")
city_field_2.send_keys("Beneficial Owner #2 City")
fill_dropdown(driver, state_field_2, "Beneficial Owner #2 State")
zip_field_2.send_keys("Beneficial Owner #2 ZIP")
fill_dropdown(driver, id_type_field_2, "State/local/tribe-issued ID")
id_number_field_2.send_keys("Beneficial Owner #2 ID number")
fill_dropdown(driver, id_country_field_2, "United States of America")
fill_dropdown(driver, id_state_field_2, "Arizona")
id_file_field_2.send_keys("beneficial/owner2/full/path/of/ID.jpeg")
email_field.send_keys("submitter email")
confirm_email_field.send_keys("submitter email confirm")
first_name_field.send_keys("submitter first name")
last_name_field.send_keys("submitter last name")
fill_field(driver, By.ID, 'rc.jurisdiction', 'reporting company country)
fill_field(driver, By.ID, 'rc.domesticState', 'reporting company state')
fill_field(driver, By.ID, 'rc.address.value', 'reporting company address')
fill_field(driver, By.ID, 'rc.city.value', 'reporting company city')
fill_field(driver, By.ID, 'rc.country.value', 'reporting company country')
fill_field(driver, By.ID, 'rc.state.value', 'reporting company state')
fill_field(driver, By.ID, 'rc.zip.value', 'reporting company zip')
#should only be true if company was established before 2024
click_element(driver, By.CSS_SELECTOR, 'label[for="rc.isExistingReportingCompany"]', use_js=True)
Code
import logging
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import WebDriverException, UnexpectedAlertPresentException, NoAlertPresentException
import os
import signal
import csv
import pandas as pd
# Configure logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
def read_companies_from_csv(file_path):
df = pd.read_csv(file_path, dtype={'EIN': str, 'SSN/ITIN': str})
return df
def update_csv(file_path, df):
df.to_csv(file_path, index=False)
def mark_company_complete(df, company_name):
df.loc[df['LLC'] == company_name, 'complete'] = 'Yes'
def wait_for_element(driver, by, value, timeout=10):
try:
element = WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((by, value))
)
return element
except Exception as e:
logger.error(f"Error waiting for element {value}: {e}")
return None
def click_element(driver, by, value, use_js=False):
element = wait_for_element(driver, by, value)
if element:
try:
if use_js:
driver.execute_script("arguments[0].click();", element)
else:
element.click()
logger.info(f"Clicked element: {value}")
except Exception as e:
logger.error(f"Error clicking element {value}: {e}")
else:
logger.error(f"Element not found to click: {value}")
def fill_field(driver, by, value, text):
element = wait_for_element(driver, by, value)
if element:
try:
element.clear()
element.send_keys(text)
element.send_keys(Keys.RETURN)
logger.info(f"Filled field {value} with text: {text}")
except Exception as e:
logger.error(f"Error filling field {value}: {e}")
else:
logger.error(f"Field not found to fill: {value}")
def click_yes_button(driver):
try:
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'button[data-testid="modal-confirm-button"]'))
)
actions = webdriver.ActionChains(driver)
actions.send_keys(Keys.TAB * 3) # Adjust the number of TAB presses as needed
actions.send_keys(Keys.ENTER)
actions.perform()
logger.info("Yes button on popup clicked using TAB and ENTER keys.")
except Exception as e:
logger.error(f"Error clicking the Yes button: {e}")
def fill_dropdown(driver, element, value):
driver.execute_script("arguments[0].scrollIntoView(true);", element)
driver.execute_script("arguments[0].click();", element)
element.send_keys(value)
element.send_keys(Keys.ENTER)
def fill_beneficial_owners(driver):
wait = WebDriverWait(driver, 10)
last_name_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].lastName.value"]')))
last_name_field.send_keys("Last Name")
logger.info("Last name field filled.")
first_name_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].firstName.value"]')))
first_name_field.send_keys("First Name")
logger.info("First name field filled.")
dob_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].dob.value"]')))
dob_field.send_keys("01/01/1982")
logger.info("Date of birth field filled.")
address_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].address.value"]')))
address_field.send_keys("Address field")
logger.info("Address field filled.")
city_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].city.value"]')))
city_field.send_keys("City")
logger.info("City field filled.")
country_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].country.value"]')))
fill_dropdown(driver, country_field, "United States of America")
logger.info("Country field filled.")
state_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].state.value"]')))
fill_dropdown(driver, state_field, "Arizona")
logger.info("State field filled.")
zip_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].zip.value"]')))
zip_field.send_keys("00000")
logger.info("ZIP code field filled.")
id_type_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].identification.type.value"]')))
fill_dropdown(driver, id_type_field, "State/local/tribe-issued ID")
logger.info("ID type field filled.")
id_number_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].identification.id.value"]')))
id_number_field.send_keys("Drivers license number")
logger.info("ID number field filled.")
id_country_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].identification.jurisdiction.value"]')))
fill_dropdown(driver, id_country_field, "United States of America")
logger.info("ID country field filled.")
id_state_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].identification.state.value"]')))
fill_dropdown(driver, id_state_field, "Arizona")
logger.info("ID state field filled.")
id_file_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[0].identification.image.value"]')))
id_file_field.send_keys("/full/path/of/ID.jpeg")
logger.info("ID file uploaded.")
add_bo_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'button[data-testid="bo-add-button"]')))
driver.execute_script("arguments[0].scrollIntoView(true);", add_bo_button)
driver.execute_script("arguments[0].click();", add_bo_button)
logger.info("Add Beneficial Owner button clicked.")
# Fill out the details for the second beneficial owner
last_name_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].lastName.value"]')))
last_name_field_2.send_keys("Beneficial Owner #2 Last Name")
logger.info("Last name field for second beneficial owner filled.")
first_name_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].firstName.value"]')))
first_name_field_2.send_keys("Beneficial Owner #2 First Name")
logger.info("First name field for second beneficial owner filled.")
dob_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].dob.value"]')))
dob_field_2.send_keys("Beneficial Owner #2 DOB")
logger.info("Date of birth field for second beneficial owner filled.")
address_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].address.value"]')))
address_field_2.send_keys("Beneficial Owner #2 Address")
logger.info("Address field for second beneficial owner filled.")
city_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].city.value"]')))
city_field_2.send_keys("Beneficial Owner #2 City")
logger.info("City field for second beneficial owner filled.")
country_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].country.value"]')))
fill_dropdown(driver, country_field_2, "United States of America")
logger.info("Country field for second beneficial owner filled.")
state_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].state.value"]')))
fill_dropdown(driver, state_field_2, "Beneficial Owner #2 State")
logger.info("State field for second beneficial owner filled.")
zip_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].zip.value"]')))
zip_field_2.send_keys("Beneficial Owner #2 ZIP")
logger.info("ZIP code field for second beneficial owner filled.")
id_type_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].identification.type.value"]')))
fill_dropdown(driver, id_type_field_2, "State/local/tribe-issued ID")
logger.info("ID type field for second beneficial owner filled.")
id_number_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].identification.id.value"]')))
id_number_field_2.send_keys("Beneficial Owner #2 ID number")
logger.info("ID number field for second beneficial owner filled.")
id_country_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].identification.jurisdiction.value"]')))
fill_dropdown(driver, id_country_field_2, "United States of America")
logger.info("ID country field for second beneficial owner filled.")
id_state_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].identification.state.value"]')))
fill_dropdown(driver, id_state_field_2, "Arizona")
logger.info("ID state field for second beneficial owner filled.")
id_file_field_2 = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="bo[1].identification.image.value"]')))
id_file_field_2.send_keys("beneficial/owner2/full/path/of/ID.jpeg")
logger.info("ID file uploaded.")
# Click the Next button to proceed to the submission page
next_button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, 'button[data-testid="bottom-next-button"]')))
driver.execute_script("arguments[0].scrollIntoView(true);", next_button)
driver.execute_script("arguments[0].click();", next_button)
logger.info("Next button clicked to proceed to submission page.")
logger.info("Beneficial owners' information filled out successfully.")
def fill_submit_page(driver):
wait = WebDriverWait(driver, 10)
# Fill out the email field
email_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="email"]')))
email_field.send_keys("submitter email")
logger.info("Email field filled.")
# Fill out the confirm email field
confirm_email_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="confirmEmail"]')))
confirm_email_field.send_keys("submitter email confirm")
logger.info("Confirm email field filled.")
# Fill out the first name field
first_name_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="firstName"]')))
first_name_field.send_keys("submitter first name")
logger.info("First name field filled.")
# Fill out the last name field
last_name_field = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '[id="lastName"]')))
last_name_field.send_keys("submitter last name")
logger.info("Last name field filled.")
# Check the "I agree" checkbox
agree_checkbox_label = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'label[for="certifyCB"]')))
driver.execute_script("arguments[0].scrollIntoView(true);", agree_checkbox_label)
driver.execute_script("arguments[0].click();", agree_checkbox_label)
logger.info("I agree checkbox selected.")
def fill_filing_information(driver):
# Agree to the terms
click_element(driver, By.CSS_SELECTOR, 'button[data-testid="agree-button"]')
time.sleep(1)
# Initial report radio button
click_element(driver, By.CSS_SELECTOR, 'label[for="fi.filingType.value1"]')
# Next button
click_element(driver, By.CSS_SELECTOR, 'button[data-testid="bottom-next-button"]', use_js=True)
def fill_reporting_company(driver, llc, ein, ssn_itin):
wait = WebDriverWait(driver, 10)
# Fill out the reporting company information
fill_field(driver, By.ID, 'rc.legalName', llc)
if pd.notna(ein):
fill_field(driver, By.ID, 'rc.taxType', 'EIN')
fill_field(driver, By.ID, 'rc.taxId', ein)
elif pd.notna(ssn_itin):
fill_field(driver, By.ID, 'rc.taxType', 'SSN/ITIN')
fill_field(driver, By.ID, 'rc.taxId', ssn_itin)
fill_field(driver, By.ID, 'rc.jurisdiction', 'reporting company country)
fill_field(driver, By.ID, 'rc.domesticState', 'reporting company state')
fill_field(driver, By.ID, 'rc.address.value', 'reporting company address')
fill_field(driver, By.ID, 'rc.city.value', 'reporting company city')
fill_field(driver, By.ID, 'rc.country.value', 'reporting company country')
fill_field(driver, By.ID, 'rc.state.value', 'reporting company state')
fill_field(driver, By.ID, 'rc.zip.value', 'reporting company zip')
# Request to receive FinCEN ID
click_element(driver, By.CSS_SELECTOR, 'label[for="rc.isRequestingId"]', use_js=True)
logger.info("Request to receive FinCEN ID checkbox selected.")
# Final Next button
click_element(driver, By.CSS_SELECTOR, 'button[data-testid="bottom-next-button"]', use_js=True)
def fill_company_applicants(driver):
# Select existing reporting company
click_element(driver, By.CSS_SELECTOR, 'label[for="rc.isExistingReportingCompany"]', use_js=True)
# Click the "Yes" button on the popup using TAB and ENTER keys
click_yes_button(driver)
# Click the next button to go to the beneficial owners page
click_element(driver, By.CSS_SELECTOR, 'button[data-testid="bottom-next-button"]', use_js=True)
def is_browser_open(driver):
try:
driver.title # Attempt to get the browser's title to check if it's still open
return True
except UnexpectedAlertPresentException:
try:
alert = driver.switch_to.alert
alert.accept()
return True
except NoAlertPresentException:
return True
except WebDriverException:
return False
def close_browser(driver):
try:
driver.quit()
except WebDriverException:
# Forcefully kill the process if quit() fails
browser_pid = driver.service.process.pid
os.kill(browser_pid, signal.SIGTERM)
def main():
# Load companies from CSV
companies_df = read_companies_from_csv('./data/companies.csv')
for index, row in companies_df.iterrows():
if pd.notna(row['complete']):
continue
llc = row['LLC']
ein = row['EIN']
ssn_itin = row['SSN/ITIN']
# Setup Chrome driver
service = Service(ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument("--start-maximized") # Add this line to open Chrome in a maximized window
driver = webdriver.Chrome(service=service, options=options)
try:
# Open the website
driver.get("https://boiefiling.fincen.gov/boir/html")
logger.info(f"Website opened successfully for {llc}.")
# Fill filing information
fill_filing_information(driver)
# Fill reporting company information
fill_reporting_company(driver, llc, ein, ssn_itin)
# Fill company applicants
fill_company_applicants(driver)
# Fill beneficial owners
fill_beneficial_owners(driver)
# Fill submission page
fill_submit_page(driver)
# Mark the company as complete in the DataFrame
companies_df.at[index, 'complete'] = 'yes'
# Save the updated CSV
update_csv('./data/companies.csv', companies_df)
logger.info(f"Form completed for {llc} and marked as complete in CSV.")
input('Press enter for next company')
finally:
close_browser(driver)
if __name__ == "__main__":
main()
Supporting CSV
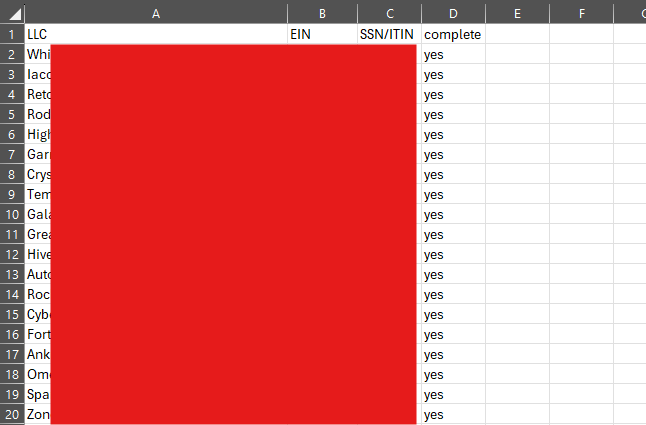
You’ll need to create a subdirectory wherever you run this program labeled ./data in this folder you can put the JPEG’s of your ID’s which must be uploaded as well as a CSV file with all of your different company names (EIN or SSN depending on how they’re setup) and a column labeled ‘complete’. The script will go through every single company automating your information but just changing these fields for each organization you own. Here is a sample of the CSV file.
BOIR E-filing API FAILED
I originally attempted to get this code to use the API provided by FinCEN you can request access here. I could not get this to format correctly based on their requirements.
THIS CODE IS NOT COMPLETE
import requests
import pandas as pd
import base64
import logging
import xml.etree.ElementTree as ET
from xml.dom import minidom
import os
import re
import api_keys
import csv
import mimetypes
from lxml import etree
import time
import xmlschema
# Setup logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
# API endpoints
AUTH_URL = 'https://iam.fincen.gov/am/oauth2/realms/root/realms/Finance/access_token'
SANDBOX_URL = 'https://boiefiling-api.user-test.fincen.gov/preprod'
PRODUCTION_URL = 'https://boiefiling-api.fincen.gov/prod'
def initialize_company_status_file(csv_path):
with open('company_status.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Company Name', 'Process ID', 'Status'])
logger.info("Company status file initialized.")
def check_file_exists(file_path):
if not os.path.exists(file_path):
logger.error(f"File not found: {file_path}")
return False
return True
def get_access_token(environment):
"""Retrieve an access token."""
logger.info("Getting access token...")
if environment == 'sandbox':
client_id = api_keys.SANDBOX_CLIENT_ID
client_secret = api_keys.SANDBOX_CLIENT_SECRET
scope = 'BOSS-EFILE-SANDBOX'
else:
client_id = api_keys.PRODUCTION_CLIENT_ID
client_secret = api_keys.PRODUCTION_CLIENT_SECRET
scope = 'BOSS-EFILE'
credentials = f"{client_id}:{client_secret}"
encoded_credentials = base64.b64encode(credentials.encode()).decode()
headers = {
'Authorization': f'Basic {encoded_credentials}',
'Content-Type': 'application/x-www-form-urlencoded'
}
data = {
'grant_type': 'client_credentials',
'scope': scope
}
response = requests.post(AUTH_URL, headers=headers, data=data)
response.raise_for_status()
return response.json().get('access_token')
def validate_attachment(file_path):
"""Validate the identifying document image attachment."""
valid_extensions = ['.jpeg', '.jpg', '.png', '.pdf']
file_size = os.path.getsize(file_path)
file_extension = os.path.splitext(file_path)[1].lower()
if file_extension not in valid_extensions:
raise ValueError(f"Invalid file format: {file_extension}. Supported formats are JPEG, JPG, PNG, PDF.")
if file_size > 4 * 1024 * 1024:
raise ValueError(f"File size exceeds the 4MB limit: {file_size} bytes.")
filename = os.path.basename(file_path)
if re.search(r'[^\w!@#$%()_\-\.=+\[\]{}|;~]', filename):
raise ValueError(f"Invalid characters in file name: {filename}")
logger.info(f"Attachment {filename} is valid.")
def save_xml_file(xml_string, filename):
"""Save XML string to a file."""
try:
with open(filename, 'w') as file:
file.write(xml_string)
logger.info(f"XML saved to {filename}")
except Exception as e:
logger.error(f"Error saving XML to file: {str(e)}")
def initiate_submission(token, base_url):
"""Initiate BOIR submission and get process ID."""
logger.info("Initiating submission...")
headers = {
'Authorization': f'Bearer {token}'
}
response = requests.get(f'{base_url}/processId', headers=headers)
response.raise_for_status()
process_id = response.json().get('processId')
logger.info(f"Obtained process ID: {process_id}")
return process_id
def upload_attachment(token, process_id, document_path, base_url):
try:
if not check_file_exists(document_path):
logger.error(f"Attachment file does not exist: {document_path}")
return 'file_not_found'
validate_attachment(document_path)
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": mimetypes.guess_type(document_path)[0]
}
with open(document_path, 'rb') as file_data:
files = {
'file': (os.path.basename(document_path), file_data, mimetypes.guess_type(document_path)[0])
}
url = f"{base_url}/attachments/{process_id}/{os.path.basename(document_path)}"
response = requests.post(url, headers=headers, files=files)
if response.status_code != 200:
logger.error(f"Failed to upload file {os.path.basename(document_path)} for process ID {process_id}. Status Code: {response.status_code}, Response: {response.text}")
return 'upload_failed'
response.raise_for_status()
return 'upload_success'
except Exception as e:
logger.error(f"Exception occurred while uploading attachment {os.path.basename(document_path)} for process ID {process_id}: {str(e)}")
return 'exception_occurred'
def upload_boir_xml(token, process_id, xml_path, base_url):
try:
if not check_file_exists(xml_path):
logger.error(f"BOIR XML file does not exist: {xml_path}")
return 'file_not_found'
logger.info(f"Uploading BOIR XML for process ID: {process_id}")
headers = {
'Authorization': f'Bearer {token}',
'Content-Type': 'application/xml'
}
xml_file_name = os.path.basename(xml_path)
with open(xml_path, 'rb') as xml_data:
response = requests.post(f'{base_url}/upload/BOIR/{process_id}/{xml_file_name}', headers=headers, data=xml_data)
if response.status_code != 200:
logger.error(f"Failed to upload BOIR XML {xml_file_name} for process ID {process_id}. Status Code: {response.status_code}, Response: {response.text}")
return 'upload_failed'
response.raise_for_status()
response_json = response.json()
if 'submissionStatus' in response_json:
logger.info(f"Upload response: {response_json}")
return response_json['submissionStatus']
logger.error(f"Upload response does not contain expected keys: {response_json}")
return 'unknown_status'
except Exception as e:
logger.error(f"Exception occurred while uploading BOIR XML {xml_file_name} for process ID {process_id}: {str(e)}")
return 'exception_occurred'
def track_submission_status(token, process_id, base_url):
"""Track the status of the BOIR submission."""
logger.info(f"Tracking submission status for process ID: {process_id}")
headers = {
'Authorization': f'Bearer {token}'
}
response = requests.get(f'{base_url}/submissionStatus/{process_id}', headers=headers)
response.raise_for_status()
return response.json().get('submissionStatus')
def log_error(response_data):
"""Log errors based on response data."""
errors = response_data.get('errors', [])
for error in errors:
error_code = error.get('ErrorCode')
error_text = error.get('ErrorText')
logger.error(f"Error Code: {error_code}, Error Text: {error_text}")
if error_code in ["SBE01", "SBE02", "SBE03", "SBE04", "SBE05", "SBE06"]:
logger.error("Recommended Action: " + error.get('ErrorText', '').split('Please')[1].strip())
def create_boir_xml(csv_row):
try:
root = ET.Element("{www.fincen.gov/base}EFilingSubmissionXML", attrib={
'xmlns:fc2': 'www.fincen.gov/base',
'xmlns:xsi': 'http://www.w3.org/2001/XMLSchema-instance',
'xsi:schemaLocation': 'www.fincen.gov/base BSA_XML_2.0.xsd',
'SeqNum': '1'
})
# Submitter Information
ET.SubElement(root, "{www.fincen.gov/base}SubmitterElectronicAddressText").text = 'EMAIL@EMAIL.com'
ET.SubElement(root, "{www.fincen.gov/base}SubmitterEntityIndivdualLastName").text = 'LAST NAME'
ET.SubElement(root, "{www.fincen.gov/base}SubmitterIndivdualFirstName").text = 'FIRST NAME'
activity = ET.SubElement(root, "{www.fincen.gov/base}Activity", attrib={'SeqNum': '2'})
ET.SubElement(activity, "{www.fincen.gov/base}ApprovalOfficialSignatureDateText").text = str(csv_row["2.date_prepared"])
ET.SubElement(activity, "{www.fincen.gov/base}FilingDateText")
activity_association = ET.SubElement(activity, "{www.fincen.gov/base}ActivityAssociation", attrib={'SeqNum': '3'})
ET.SubElement(activity_association, "{www.fincen.gov/base}InitialReportIndicator").text = "Y" if str(csv_row["1.a"]).upper() == "Y" else ""
ET.SubElement(activity_association, "{www.fincen.gov/base}CorrectsAmendsPriorReportIndicator").text = "Y" if str(csv_row["1.b"]).upper() == "Y" else ""
ET.SubElement(activity_association, "{www.fincen.gov/base}UpdatesPriorReportIndicator").text = "Y" if str(csv_row["1.c"]).upper() == "Y" else ""
ET.SubElement(activity_association, "{www.fincen.gov/base}NewlyExemptEntityIndicator").text = "Y" if str(csv_row["1.d"]).upper() == "Y" else ""
# Reporting Company Information
reporting_company = ET.SubElement(activity, "{www.fincen.gov/base}Party", attrib={'SeqNum': '4'})
ET.SubElement(reporting_company, "{www.fincen.gov/base}ActivityPartyTypeCode").text = "62"
ET.SubElement(reporting_company, "{www.fincen.gov/base}ExistingReportingCompanyIndicator").text = "Y" if str(csv_row["16"]).upper() == "Y" else ""
ET.SubElement(reporting_company, "{www.fincen.gov/base}FormationCountryCodeText").text = str(csv_row["10.a"])
ET.SubElement(reporting_company, "{www.fincen.gov/base}FormationStateCodeText").text = str(csv_row["10.b"])
ET.SubElement(reporting_company, "{www.fincen.gov/base}RequestFinCENIDIndicator").text = "Y"
party_name = ET.SubElement(reporting_company, "{www.fincen.gov/base}PartyName", attrib={'SeqNum': '5'})
ET.SubElement(party_name, "{www.fincen.gov/base}PartyNameTypeCode").text = "L"
ET.SubElement(party_name, "{www.fincen.gov/base}RawPartyFullName").text = str(csv_row["5"])
address = ET.SubElement(reporting_company, "{www.fincen.gov/base}Address", attrib={'SeqNum': '6'})
ET.SubElement(address, "{www.fincen.gov/base}RawCityText").text = str(csv_row["12"])
ET.SubElement(address, "{www.fincen.gov/base}RawCountryCodeText").text = "US"
ET.SubElement(address, "{www.fincen.gov/base}RawStateCodeText").text = str(csv_row["14"])
ET.SubElement(address, "{www.fincen.gov/base}RawStreetAddress1Text").text = str(csv_row["11"])
ET.SubElement(address, "{www.fincen.gov/base}RawZIPCode").text = str(csv_row["15"])
party_identification = ET.SubElement(reporting_company, "{www.fincen.gov/base}PartyIdentification", attrib={'SeqNum': '7'})
ET.SubElement(party_identification, "{www.fincen.gov/base}PartyIdentificationNumberText").text = str(csv_row["8"])
ET.SubElement(party_identification, "{www.fincen.gov/base}PartyIdentificationTypeCode").text = str(csv_row["7"])
# Company Applicant Information
company_applicant = ET.SubElement(activity, "{www.fincen.gov/base}Party", attrib={'SeqNum': '8'})
ET.SubElement(company_applicant, "{www.fincen.gov/base}ActivityPartyTypeCode").text = "63"
ET.SubElement(company_applicant, "{www.fincen.gov/base}IndividualBirthDateText").text = str(csv_row["23"])
party_name = ET.SubElement(company_applicant, "{www.fincen.gov/base}PartyName", attrib={'SeqNum': '9'})
ET.SubElement(party_name, "{www.fincen.gov/base}PartyNameTypeCode").text = "L"
ET.SubElement(party_name, "{www.fincen.gov/base}RawEntityIndividualLastName").text = str(csv_row["19"])
ET.SubElement(party_name, "{www.fincen.gov/base}RawIndividualFirstName").text = str(csv_row["20"])
ET.SubElement(party_name, "{www.fincen.gov/base}RawIndividualMiddleName").text = str(csv_row["21"])
ET.SubElement(party_name, "{www.fincen.gov/base}RawIndividualNameSuffixText").text = str(csv_row["22"])
address = ET.SubElement(company_applicant, "{www.fincen.gov/base}Address", attrib={'SeqNum': '10'})
ET.SubElement(address, "{www.fincen.gov/base}RawCityText").text = str(csv_row["26"])
ET.SubElement(address, "{www.fincen.gov/base}RawCountryCodeText").text = str(csv_row["27"])
ET.SubElement(address, "{www.fincen.gov/base}RawStateCodeText").text = str(csv_row["28"])
ET.SubElement(address, "{www.fincen.gov/base}RawStreetAddress1Text").text = str(csv_row["25"])
ET.SubElement(address, "{www.fincen.gov/base}RawZIPCode").text = str(csv_row["29"])
if str(csv_row["24"]) == "Business address":
ET.SubElement(address, "{www.fincen.gov/base}BusinessAddressIndicator").text = "Y"
else:
ET.SubElement(address, "{www.fincen.gov/base}ResidentialAddressIndicator").text = "Y"
party_identification = ET.SubElement(company_applicant, "{www.fincen.gov/base}PartyIdentification", attrib={'SeqNum': '11'})
ET.SubElement(party_identification, "{www.fincen.gov/base}OtherIssuerCountryText").text = str(csv_row["32.a"])
ET.SubElement(party_identification, "{www.fincen.gov/base}OtherIssuerStateText").text = str(csv_row["32.b"])
ET.SubElement(party_identification, "{www.fincen.gov/base}PartyIdentificationNumberText").text = str(csv_row["31"])
ET.SubElement(party_identification, "{www.fincen.gov/base}PartyIdentificationTypeCode").text = str(csv_row["30"])
ET.SubElement(party_identification, "{www.fincen.gov/base}OriginalAttachmentFileName").text = str(csv_row["33"])
# Beneficial Owner Information
seq_num = 12
for i in range(1, 3):
if f'38.{i}' in csv_row:
beneficial_owner = ET.SubElement(activity, "{www.fincen.gov/base}Party", attrib={'SeqNum': str(seq_num)})
ET.SubElement(beneficial_owner, "{www.fincen.gov/base}ActivityPartyTypeCode").text = "64"
ET.SubElement(beneficial_owner, "{www.fincen.gov/base}IndividualBirthDateText").text = str(csv_row.get(f'42.{i}', ""))
if str(csv_row.get(f'37.{i}', "")).upper() == "Y":
ET.SubElement(beneficial_owner, "{www.fincen.gov/base}ExemptIndicator").text = "Y"
ET.SubElement(beneficial_owner, "{www.fincen.gov/base}PartyName", attrib={'SeqNum': str(seq_num + 1)})
ET.SubElement(beneficial_owner, "{www.fincen.gov/base}RawEntityIndividualLastName").text = str(csv_row.get(f'38.{i}', ""))
else:
party_name = ET.SubElement(beneficial_owner, "{www.fincen.gov/base}PartyName", attrib={'SeqNum': str(seq_num + 1)})
ET.SubElement(party_name, "{www.fincen.gov/base}PartyNameTypeCode").text = "L"
ET.SubElement(party_name, "{www.fincen.gov/base}RawEntityIndividualLastName").text = str(csv_row.get(f'38.{i}', ""))
ET.SubElement(party_name, "{www.fincen.gov/base}RawIndividualFirstName").text = str(csv_row.get(f'39.{i}', ""))
ET.SubElement(party_name, "{www.fincen.gov/base}RawIndividualMiddleName").text = str(csv_row.get(f'40.{i}', ""))
ET.SubElement(party_name, "{www.fincen.gov/base}RawIndividualNameSuffixText").text = str(csv_row.get(f'41.{i}', ""))
address = ET.SubElement(beneficial_owner, "{www.fincen.gov/base}Address", attrib={'SeqNum': str(seq_num + 2)})
ET.SubElement(address, "{www.fincen.gov/base}RawCityText").text = str(csv_row.get(f'44.{i}', ""))
ET.SubElement(address, "{www.fincen.gov/base}RawCountryCodeText").text = str(csv_row.get(f'45.{i}', ""))
ET.SubElement(address, "{www.fincen.gov/base}RawStateCodeText").text = str(csv_row.get(f'46.{i}', ""))
ET.SubElement(address, "{www.fincen.gov/base}RawStreetAddress1Text").text = str(csv_row.get(f'43.{i}', ""))
ET.SubElement(address, "{www.fincen.gov/base}RawZIPCode").text = str(csv_row.get(f'47.{i}', ""))
party_identification = ET.SubElement(beneficial_owner, "{www.fincen.gov/base}PartyIdentification", attrib={'SeqNum': str(seq_num + 3)})
ET.SubElement(party_identification, "{www.fincen.gov/base}OtherIssuerCountryText").text = str(csv_row.get(f'50.{i}.a', ""))
ET.SubElement(party_identification, "{www.fincen.gov/base}OtherIssuerStateText").text = str(csv_row.get(f'50.{i}.b', ""))
ET.SubElement(party_identification, "{www.fincen.gov/base}IssuerLocalTribalCodeText").text = str(csv_row.get(f'50.{i}.c', ""))
ET.SubElement(party_identification, "{www.fincen.gov/base}OtherIssuerLocalTribalText").text = str(csv_row.get(f'50.{i}.d', ""))
ET.SubElement(party_identification, "{www.fincen.gov/base}PartyIdentificationNumberText").text = str(csv_row.get(f'49.{i}', ""))
ET.SubElement(party_identification, "{www.fincen.gov/base}PartyIdentificationTypeCode").text = str(csv_row.get(f'48.{i}', ""))
ET.SubElement(party_identification, "{www.fincen.gov/base}OriginalAttachmentFileName").text = str(csv_row.get(f'51.{i}', ""))
seq_num += 4
xml_str = prettify_xml(root)
logger.debug(f"Generated XML: {xml_str}")
if validate_xml(xml_str):
return xml_str
else:
return None
except Exception as e:
logger.error(f"Error creating BOIR XML: {str(e)}")
return None
def prettify_xml(elem):
"""Return a pretty-printed XML string for the Element."""
rough_string = ET.tostring(elem, 'utf-8')
reparsed = minidom.parseString(rough_string)
return reparsed.toprettyxml(indent=" ")
def validate_xml(xml_str):
"""Validate the structure of the XML string using the provided XSD schema."""
try:
schema_bsa = xmlschema.XMLSchema("BSA_XML_2.0.xsd")
schema_boir = xmlschema.XMLSchema("BOIRSchema.xsd.xml")
schema_bsa.validate(xml_str)
schema_boir.validate(xml_str)
logger.info("XML structure is valid.")
return True
except xmlschema.XMLSchemaException as e:
logger.error(f"XML schema validation error: {e}")
return False
except Exception as e:
logger.error(f"XML parsing error: {e}")
return False
def check_submission_status(token, process_id, base_url, retry_count=3, retry_delay=5):
"""Check the status of a BOIR submission."""
headers = {
'Authorization': f'Bearer {token}'
}
for attempt in range(retry_count):
try:
response = requests.get(f'{base_url}/submissionStatus/{process_id}', headers=headers)
if response.status_code == 200:
submission_status = response.json().get('submissionStatus')
logger.info(f"Submission status for process ID {process_id}: {submission_status}")
if submission_status == 'submission_validation_failed':
error_details = response.json().get('validationErrors', ['Unknown error'])[0]
logger.debug(f'Failed with {response.json()}')
log_error(response.json())
return submission_status, error_details
return submission_status, None
else:
logger.error(f"Failed to retrieve submission status for process ID {process_id}. Status code: {response.status_code}")
logger.error(f"Response content: {response.text}")
if attempt < retry_count - 1:
logger.info(f"Retrying in {retry_delay} seconds...")
time.sleep(retry_delay)
except requests.exceptions.RequestException as e:
logger.error(f"Error occurred while checking submission status for process ID {process_id}: {str(e)}")
if attempt < retry_count - 1:
logger.info(f"Retrying in {retry_delay} seconds...")
time.sleep(retry_delay)
logger.error(f"Failed to retrieve submission status for process ID {process_id} after {retry_count} attempts.")
return None, None
def check_csv_format(filename):
"""
Check the format and values in the BOIR CSV file before proceeding.
"""
required_fields = {
"1.a": r"^[YN]$",
"1.b": r"^[YN]$",
"1.c": r"^[YN]$",
"1.d": r"^[YN]$",
"2.date_prepared": r"^\d{8}$",
"5": r"^.{1,150}$",
"8": r"^\d{9}$",
"10.a": r"^[A-Z]{2}$",
"10.b": r"^[A-Z]{2}$",
"11": r"^.{1,100}$",
"12": r"^.{1,50}$",
"13": r"^[A-Z]{2}$",
"14": r"^[A-Z]{2}$",
"15": r"^\d{5}$",
"23": r"^\d{8}$",
"25": r"^.{1,100}$",
"26": r"^.{1,50}$",
"27": r"^[A-Z]{2}$",
"28": r"^[A-Z]{2}$",
"29": r"^\d{5}$",
"31": r"^.{1,25}$",
"32.a": r"^[A-Z]{2}$",
"32.b": r"^[A-Z]{2}$",
"51.1": r"^.+\.(jpg|jpeg|png|pdf)$",
# Add patterns for any additional fields required
}
def check_value(field, value):
if field in required_fields:
pattern = required_fields[field]
if not re.match(pattern, value):
logger.error(f"Field {field} has invalid value: {value}")
return False
return True
def check_file_exists(file_path):
if not os.path.exists(file_path):
logger.error(f"File not found: {file_path}")
return False
return True
# Check CSV file
with open(filename, 'r') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
for field, value in row.items():
if not check_value(field, value):
return False
if field.endswith('.1') or field.endswith('.2'): # Handle repeating fields
if field.startswith('51'): # Check if it's a document path
document_path = os.path.join('./data', value)
if not check_file_exists(document_path):
return False
logger.info("CSV file format and values are correct.")
return True
def update_company_status(company_name, process_id, submission_status, error_details=''):
"""Update the company status in the CSV file."""
updated = False
if not os.path.exists('./data/company_status.csv'):
with open('./data/company_status.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['company_name', 'process_id', 'status', 'error_details'])
with open('./data/company_status.csv', 'r', newline='') as orig_file:
reader = csv.reader(orig_file)
rows = list(reader)
with open('./data/company_status_temp.csv', 'w', newline='') as temp_file:
writer = csv.writer(temp_file)
for row in rows:
if row[0] == company_name:
row[1] = process_id
row[2] = submission_status
row[3] = error_details if error_details else ''
updated = True
writer.writerow(row)
if not updated:
writer.writerow([company_name, process_id, submission_status, error_details])
os.replace('./data/company_status_temp.csv', './data/company_status.csv')
def register_organizations(csv_path, environment):
"""Read CSV and register organizations."""
if not check_csv_format(csv_path):
logger.error("CSV file format or values are incorrect. Please check the log for details.")
return
df = pd.read_csv(csv_path)
base_url = SANDBOX_URL if environment == 'sandbox' else PRODUCTION_URL
token = get_access_token(environment)
if not token:
logger.error("Failed to obtain access token. Exiting.")
return
companies = df.to_dict('records')
if not os.path.exists('./data/company_status.csv'):
with open('./data/company_status.csv', 'w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['company_name', 'process_id', 'status', 'error_details'])
for company in companies:
company_name = company.get('5', 'Unknown Company')
process_id = None
skip_company = False
with open('./data/company_status.csv', 'r', newline='') as file:
reader = csv.reader(file)
for row in reader:
if row[0] == company_name:
process_id = row[1]
current_status, _ = check_submission_status(token, process_id, base_url)
if current_status:
logger.info(f"Current status for {company_name}: {current_status}")
update_company_status(company_name, process_id, current_status)
if current_status in ['submission_initiated', 'submission_validation_failed', 'submission_failed']:
skip_company = False
else:
skip_company = True
else:
skip_company = True
break
if skip_company:
continue
try:
if process_id is None:
process_id = initiate_submission(token, base_url)
if process_id is None:
logger.error(f"Failed to obtain process ID for {company_name}")
continue
xml_filename = f"boir_{company_name.replace(' ', '_')}.xml"
boir_xml = create_boir_xml(company)
if boir_xml is None:
logger.error(f"Failed to create BOIR XML for {company_name}")
continue
save_xml_file(boir_xml, f"./data/{xml_filename}")
document_paths = [f"./data/{company[key]}" for key in company if re.match(r"^51\.\d+$", key) and os.path.exists(f"./data/{company[key]}")]
if not document_paths:
logger.error(f"No valid document paths found for {company_name}")
continue
for document_path in document_paths:
upload_status = upload_attachment(token, process_id, document_path, base_url)
if upload_status == 'submission_exists':
logger.info(f"Submission already exists for process ID {process_id}. Skipping attachment upload.")
continue
elif upload_status != 'upload_success':
logger.error(f"Failed to upload attachment for {company_name}. Status: {upload_status}")
continue
boir_status = upload_boir_xml(token, process_id, f"./data/{xml_filename}", base_url)
if boir_status == 'submission_initiated':
update_company_status(company_name, process_id, boir_status)
elif boir_status == 'submission_exists':
logger.info(f"Submission already exists for process ID {process_id}. Skipping BOIR XML upload.")
else:
logger.error(f"Failed to upload BOIR XML for {company_name}. Status: {boir_status}")
continue
final_status = track_submission_status(token, process_id, base_url)
logger.info(f"Final status for {company_name}: {final_status}")
if final_status in ['submission_accepted', 'submission_rejected']:
retrieve_transcript(token, process_id, base_url)
if final_status == 'submission_rejected':
response_data = track_submission_status(token, process_id, base_url)
log_error(response_data)
time.sleep(5) # Delay between each company registration
except requests.exceptions.RequestException as e:
logger.error(f"Request error for {company_name}: {str(e)}")
except Exception as e:
logger.error(f"Error processing {company_name}: {str(e)}")
def verify_submissions():
"""Verify the submission status of all companies."""
if not os.path.exists('./data/company_status.csv'):
logger.error("Company status CSV file not found. No submissions to verify.")
return
token = get_access_token(environment)
base_url = SANDBOX_URL if environment == 'sandbox' else PRODUCTION_URL
if not token:
logger.error("Failed to obtain access token. Exiting.")
return
with open('./data/company_status.csv', 'r', newline='') as file:
reader = csv.reader(file)
next(reader) # Skip header row
for row in reader:
company_name = row[0]
process_id = row[1]
submission_status, error_details = check_submission_status(token, process_id, base_url)
if submission_status:
logger.info(f"Updated status for {company_name}: {submission_status}")
update_company_status(company_name, process_id, submission_status, error_details if error_details else '')
def generate_summary_report():
"""Generate a summary report of the registration status."""
if not os.path.exists('./data/company_status.csv'):
logger.error("Company status CSV file not found. No submissions to report.")
return
total_companies = 0
successful_submissions = 0
failed_submissions = 0
with open('./data/company_status.csv', 'r', newline='') as file:
reader = csv.reader(file)
next(reader) # Skip header row
for row in reader:
total_companies += 1
if row[2] == 'submission_accepted':
successful_submissions += 1
elif row[2] == 'submission_rejected':
failed_submissions += 1
logger.info("Registration Summary Report")
logger.info(f"Total Companies: {total_companies}")
logger.info(f"Successful Submissions: {successful_submissions}")
logger.info(f"Failed Submissions: {failed_submissions}")
if failed_submissions > 0:
logger.info("Please check the company status CSV file for details on failed submissions.")
def monitor_and_update():
"""Continuously monitor and update the registration status."""
while True:
verify_submissions()
time.sleep(3600) # Wait for 1 hour before checking again
if __name__ == "__main__":
csv_path = './data/boir_data.csv'
environment = 'sandbox' # or 'production'
register_organizations(csv_path, environment)
verify_submissions()
generate_summary_report()
monitor_and_update()
Supporting CSV
This code requires a ./data/boir_data.csv file which contains the following column which correspond to each section on the BOIR form.