I’m always on the hunt for an edge in the markets. After finishing Nate Silver’s book, “On the Edge: The Art of Risking Everything.” this week I thought it would be fitting to write a blog post about an arbitrage opportunity
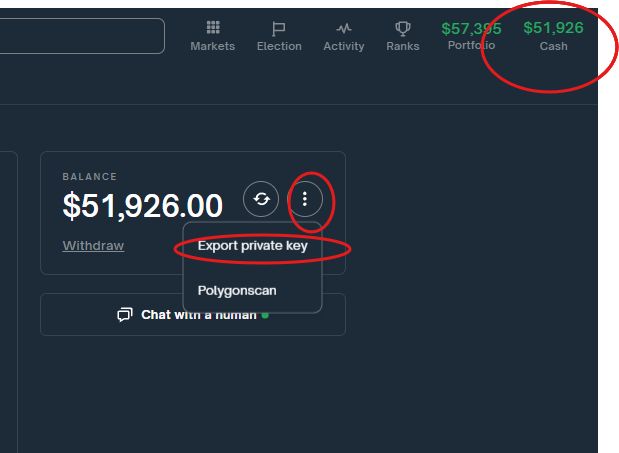
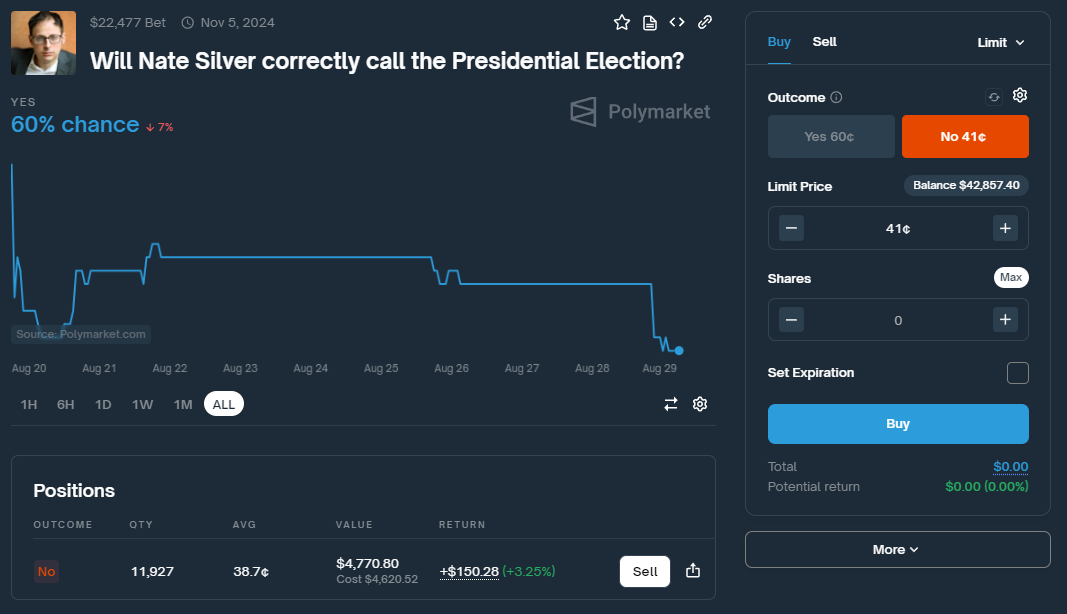
Ironically I’m placing a bet against him on Polymarket.com…. Ok, maybe not technically against him. But earlier today I bought 11,927 ‘No’ shares that he would not call the Presidential election. What’s funny about this position is I think he will accurately call the election. Or at least there is a better than 50/50 chance he will call the election. Making this a bad bet.
You might be wondering why I would do this if I didn’t think it would profit. I will explain how to profit by betting against Nate Silver’s election predictions—a strategy that, if executed correctly, can offer a guaranteed win or at least a break-even outcome, all while potentially yielding a 54% yield on your investment. In this post, I’ll walk you through the mechanics, the math behind it, and how to manage your bets leading up to election day.
The Opportunity: Betting Against Nate Silver
Nate Silver is a well-known figure in election forecasting, and platforms like Polymarket.com allow you to bet on whether he will correctly predict an election outcome. Here’s the edge: you can bet that Nate Silver will be wrong while simultaneously betting on the candidate he predicts to win. If you play it right, this creates a no-risk scenario where you can either break even or secure a small profit with an annualized return of up to 54% (the trade only lasts for 67 days so you won’t actually make 54% this is however the annual yield)
“To succeed in a world full of uncertainty, one must adopt the mindset of the fox, always ready to pivot and re-evaluate when new data presents itself.”
While I might be exploiting a flaw in prediction markets here, Silver’s insights are invaluable for understanding how to think critically about risk and predictions. It’s a reminder that the best strategies are those that remain agile and open to new information.
The Math That Makes It Work
Here’s how it works:
Bet on “NO” for Nate Silver being wrong: Cost  cents.
cents.
Bet on the candidate Nate Silver predicts to win: This cost  will fluctuate based on the odds, but here’s where it gets interesting.
will fluctuate based on the odds, but here’s where it gets interesting.
Conditional Formula
To ensure you either break even or make a profit, here’s the formula to follow:
![\[P =\begin{cases}1 - (C_N + C_C), & \text{if } (C_N + C_C) \leq 1 \\\text{Do not place the bet}, & \text{if } (C_N + C_C) > 1\end{cases}\]](https://jeremywhittaker.com/wp-content/ql-cache/quicklatex.com-2d3be626f97940a714c065dd5db64f42_l3.png "Rendered by QuickLaTeX.com")
This means:
If  : You place the bet, knowing you’ll either break even or profit.
: You place the bet, knowing you’ll either break even or profit.
If  : You skip the candidate bet altogether to avoid a loss.
: You skip the candidate bet altogether to avoid a loss.
Setting and Managing Your Limit Orders
Nate Silver’s predictions are updated multiple times per week as new data comes in. To optimize this strategy you have to do two things:
- You have to set a limit order at the inverse of your price that you bought ‘No’ shares for Nate Silver. This will ensure that you break even.

- As election day moves closer and you are confident that Nate’s predictions are not going to flip you should lock in your profits by buying the candidate that he predicts will win. You must place this trade or you will not be hedged! And if the cost to buy ‘No’ on Nate Silver and the cost of the candidate exceeds 1 you will lose money.

My Take: A Tight Race Expected
In my opinion, this election is likely to be a close one—a virtual coin toss with odds hovering around 50/50. Given this, the potential profit from this strategy might be around 10%, assuming the market prices stay within a reasonable range. With 67 days left until the election, this profit can be annualized to provide a significant APR.
To calculate the APR, you can use the formula:
![\[\text{APR} = \left( \frac{\text{Profit}}{\text{Investment}} \right) \times \left( \frac{365}{\text{Days until Election}} \right)\]](https://jeremywhittaker.com/wp-content/ql-cache/quicklatex.com-ddeb354db8afaccd3abd443e6eeffb60_l3.png "Rendered by QuickLaTeX.com")
So, if you’re making about a 10% return over 67 days:
![\[\text{APR} = 0.10 \times \left( \frac{365}{67} \right) \approx 0.54 \text{ or } 54\%\]](https://jeremywhittaker.com/wp-content/ql-cache/quicklatex.com-88cefe0bafb652d5677756550e161155_l3.png "Rendered by QuickLaTeX.com")
Unfortunately, Liquidity is an Issue
As promising as this strategy sounds, there’s one significant drawback: liquidity. I was only able to purchase 11,927 shares of Nate Silver being wrong and 4,266 shares of 538 calling the election for less than 39 cents. Essentially, I bought both trades as they represent the same underlying outcome. This lack of liquidity means that your ability to place large bets or move in and out of positions may be limited, potentially affecting the profitability of this strategy.
Definitions, The Fine Print
One crucial aspect of this strategy that needs to be understood is the timing of Nate Silver’s predictions. Typically, Nate Silver and his team at FiveThirtyEight may continue to update their forecasts until the very last moment—sometimes even until the morning of election day. This means that the candidate Nate predicts to win could change at the last minute, potentially complicating the execution of your bet on the winning candidate.
If Silver’s prediction is “frozen” too late, it may reduce the amount of time you have to place your bet, making it harder to lock in the favorable odds that ensure a profit. Additionally, a last-minute change in prediction could cause significant fluctuations in the betting market, making it difficult to execute your planned hedge. This “fine print” detail is something you should be acutely aware of when executing this strategy, as it could impact your ability to successfully carry out the arbitrage.
In short, while the strategy seems straightforward, the timing of when the prediction is finalized adds a layer of complexity that must be considered to avoid potential pitfalls. It is critical to monitor the forecast updates closely and be prepared to act quickly when the prediction is frozen to maximize the chances of executing the arbitrage successfully.
Is This Actually Arbitrage?
While this strategy appears to be a form of arbitrage, it’s important to recognize that certain unforeseen events could complicate the situation. For example, if one of the candidates were to die before the election, the market dynamics could change dramatically. The sudden withdrawal of a candidate would likely cause a market upheaval, potentially voiding some bets or causing severe losses. This is a reminder that even in what appears to be a “sure thing,” there are always risks that need to be considered. Thus, while this strategy mimics the characteristics of arbitrage, it’s not entirely free of risk.
Conclusion
This arbitrage opportunity isn’t about taking big risks for big rewards. Instead, it’s about leveraging market inefficiencies to guarantee yourself a win, however small. By betting that Nate Silver will be wrong and strategically placing a bet on the candidate he predicts to win, you’re setting yourself up for a situation where the numbers work in your favor—as long as you stick to the math. Just remember, the total cost must not exceed $1. If it does, walk away and wait for the next opportunity.
And if you’re interested in diving deeper into understanding risk and decision-making, I highly recommend Nate Silver’s book “On the Edge: The Art of Risking Everything.” It’s packed with insights on how to think like a fox—adaptable, curious, and always ready to revise your beliefs when new evidence comes to light.